
안녕하세요, MoonLight입니다.
오늘은 얼굴 인식 Model의 성능 측정에 많이 사용되는 LFW Dataset에 대해서 알아보도록 하겠습니다.
최근에 얼굴 인식 관련 Model일을 하게 되면서 접하게 되었는데, 광범위하게 많이 사용되는 것 같아서 한 번 정리해 보려고 합니다.
0. 소개
2009년에 공개된 LFW Dataset은 Web상에서 총 5749명의 유명인에 대해서 취득된 13233장의 사진으로 구성되어 있습니다.
기존에 제약된 환경에서 촬영된 얼굴 사진 Dataset(FERET , MultiPIE)와 비교했을 때 상대적으로 일상생활에서 나타나는 조명이나
표정, 그리고 포즈변화 등 다양한 변화가 포함되어 있기 때문에 얼굴 인식 Model 성능 검증을 위해 널리 활용되고 있습니다.
Dataset의 구조에 대해서 조금 더 자세히 알아보면, 앞서 말씀드렸듯이 총 5749명의 유명인의 사진이 있습니다.
하지만, 얼굴 인식 Model의 검증을 위해서는 동일인과 다른 사람의 얼굴 비교가 반드시 필요하기 때문에
같은 인물에 대해서 최소 2장 이상이 있는 인물의 Data만이 유용합니다.
조사해 보면 5749명의 인물 중 2장 이상의 사진이 있는 경우는 총 1680명이며, 이를 잘 조합하여 검증 Dataset으로써 활용하는 것입니다.
좀 더 자세한 내용은 아래 Link를 참고해 주시기 바랍니다.
1. Download
2. Usage
홈페이지에 보시면, 이 Dataset의 사용법에 대한 예시를 찾아볼 수 있는데, 크게 Model Development와 Model Benchmark시로 나누어서 설명하고 있습니다.
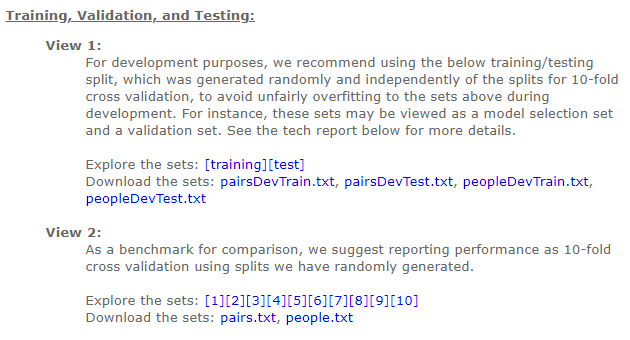
2.0. Model Development
미리 Random하게 나누어 놓은 10-Fold Cross Validation Dataset을 이용하기를 권장하고 있습니다.
아래에 미리 나누어 놓은 TXT File을 참고하여 Model Train에 이용할 수 있습니다.
2.1. Model Benchmark
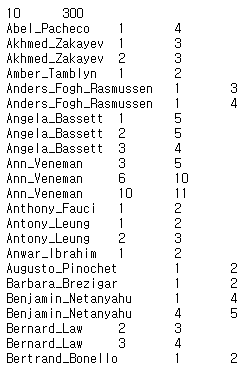
Model 성능 Benchmark에서는 pairs.txt 파일을 사용하고 있는데, 이는 많은 얼굴 인식 Model에서 사용하고 있더라구요.
FaceNet에서도 LFW Dataset을 이용한 Validation시에 이 File을 사용하고 있었습니다.
이 File을 열어보면, 첫째줄에 10 300이라고 나오는데, 이 숫자의 뜻은 같은 사람 Data 300개 / 다른 사람 Data 300개씩 묶음이 모두 10개로 구성되어 있다는 의미입니다.

오늘은 얼굴 인식 관련 Deep Learning Model에서 많이 사용되는 Dataset인 LFW Dataset에 대해서 알아보았습니다.
그럼, 다음에 또 만나요~!
'Deep_Learning' 카테고리의 다른 글
| No module named 'PIL' 오류 해결 방법 (0) | 2024.01.31 |
|---|---|
| TFLite File 다루기 (1) | 2024.01.29 |
| import __future__ 구문의 의미 (2) | 2024.01.11 |
| Deep Learning Compiler 종류 (1) | 2024.01.02 |
| ONNX(Open Neural Network Exchange) (1) | 2023.12.06 |