
728x90
안녕하세요, MoonLight입니다.
오늘은 널리 쓰이고 있는 Deep Learning Compiler 몇 가지를 살펴보도록 하겠습니다.
1. TVM
1.0. Overview

- TVM은 CPU , GPU 그 외의 다른 Deep Learning Accelerator들에 맞게 Model을 Compile하는 Framework입니다.
- 다양한 Hardware Backend에 맞게 Model을 최적화하고 효율적으로 계산하도록 만들어 줍니다.
1.1. Conversion & Optimization
- TVM이 Model을 최적화하고 Machine Code를 생성하는 방법을 소개하도록 하겠습니다.

- 변환하고자 하는 Tensorflow / PyTorch / Onnx File을 입력 받습니다.
- TVM의 High Level Model Language인 ‘Relay’ 형태로 변환합니다.
- TE(Tensor Expression) 형태로 Lowering을 합니다. Lowering이란 High-Level Representation에서 Low-Level Representation으로 바꾸는 것을 말합니다. High-Level Optimizations을 수행하고 난 후에, Relay는 FuseOps이라는 것을 수행하여 여러개의 Subgraph로 쪼개고, 여러개의 Subgraph를 TE로 Lowering합니다. TE는 Tensor Computations을 나타내는 Domain-Specific Language이며, Tiling, Vectorization, Parallelization, Unrolling, Fusion과 같은 Low-Level Loop Optimizations도 수행합니다.
- AutoTVM 이나 AutoScheduler과 같은 Auto-Tuning Module을 이용하여 최적의 Schedule을 찾습니다.
- Compile하기 전에 최적의 설정을 찾습니다. Tuning이 끝나면 Auto-Tuning Module은 개별 Subgraph의 최고의 Schedule을 찾습니다.
- 개별 Subgraph는 TVM의 Low-Level Intermediate Representation인 TIR ( Tensor Intermediate Representation )로 Lowering되고 Low-Level Optimization이 수행됩니다. 마지막으로, TIR은 각 개별 Hardware에 맞게 Target Compiler로 Lowering됩니다. TVM이 지원하는 Backend 종류에는 다음과 같은 것이 있습니다.
- LLVM : Standard x86 , ARM processors, AMDGPU , NVPTX로 Code Generation
- NVCC : NVIDIA Compiler
- TVM’s Bring Your Own Coegen (BYOC)
- Machine Code로 Compile합니다.
1.2. Install
- TVM은 다양한 방법의 Install 방식을 제공합니다.
- 구체적인 방법은 아래 Link를 참고하시기 바랍니다
1.3. Tutorial
- 아래의 Link를 참고하면 우리의 Model을 TVM을 이용해서 각 Backend HW에 적합한 Code로 변환하는 일련의 순서를 Python API를 이용해서 보여주고 있습니다.
- 생각보다 간단하네요
1.4. Support Target List
- TVM으로 생성 가능한 Backend Target 관련 정보는 아래의 API를 통해서 알 수 있습니다.
2. XLA(Accelerated Linear Algebra)
2.0. Overview
-
- XLA(Accelerated Linear Algebra)는 TensorFlow 모델의 실행 시간을 가속화하기 위한 선형 대수 특화 컴파일러입니다.기만 하면 됩니다.
- TensorFlow 모델을 소스 코드 변경 없이 가속화할 수 있다고는 하지만, 예제를 보면, 가속이 필요한 부분의 Source를 조금 수정을 하는 모습을 볼 수 있었습니다.
- TensorFlow 모델만을 가속할 수 있는 것 처럼 들리지만, 실제로는 JAX 심지어 PyTorch까지도 가속할 수 있습니다.
- XLA는 Tensorflow Package에 포함되어 있고, 가속을 하려는 함수에 tf.function이라는 Wrapping Function을 사용하면 XLA 가속이 가능합니다.
- tf.function는 Tensorflow Function을 포함하는 어떤 Function에서도 사용이 가능하므로, Inference 이외에도 사용이 가능합니다.
- 사용하는 방법은 tf.function을 사용할 때, jit_compile=True 인자를 추가하기만 하면 됩니다.
2.1. Examples
-
- 간단하게 XLA를 기존 Code에 적용하는 예제를 살펴보도록 하겠습니다.
- 다음과 같은 Code가 있다고 해봅시다.
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)위 모델은 차원이 (10, )인 입력을 받아서, 다음과 같이 하면 결과가 나옵니다.
# 모델에 대한 임의의 입력을 생성합니다.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# 순전파를 실행합니다.
_ = model(random_inputs)
위의 예제를 XLA를 이용하는 Code로 바꾸려면, 아래와 같이 하면 됩니다.
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
-
- Model의 기본 call()함수를 XLA에 사용하려면 위와 같이 하면되지만, 임의의 함수를 XLA에 적용하려면 아래와 같이 하면 됩니다.
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
2.2. Conversion & Optimization
-
- XLA 입력에 사용되는 언어를 “HLO IR” 또는 HLO(High Level Operations)라고 하는데, 간단하게 compiler IR이라고 생각하면 됩니다.
- XLA는 HLO에 정의된 Graph(“computations”)를 가져와서 다양한 하드웨어 아키텍처에 맞는 machine instructions로 Compile합니다.
- XLA는 모듈식 구성으로 되어 있어서 다양한 하드웨어 아키텍처에 맞게 바꿀 수 있는 장점이 있습니다.
- x64 및 ARM64용 CPU 백엔드 뿐만 아니라 NVIDIA GPU 백엔드도 TensorFlow 소스 트리에 있습니다.
- 다음 다이어그램은 XLA의 컴파일 프로세스를 보여줍니다.
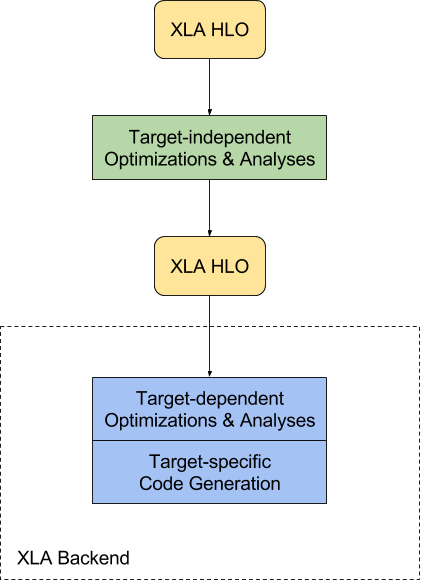
- XLA는 먼저 CSE , target-independent operation fusion , buffer analysis for allocating runtime memory for the computation와 같은 target-independent한 optimizations과 analysis를 거칩니다.
- target-independent 작업을 마친 후에 XLA는 HLO computation을 Backend로 보냅니다.
- backend는 추가적인 HLO Level의 Optimization을 수행하고, 이 때에 Target의 정보가 필요합니다
- 이 단계에서는 backend가 특정 작업 혹은 패턴 조합을 일치시켜서 최적화된 Library 호출을 수행할 수도 있습니다.
- 다음 단계는 target-specific code generation입니다.
- XLA가 지원하는 Backend는 low-level IR, optimization, code-generation에 LLVM을 사용합니다.
- Backend는 XLA HLO computation을 효율적으로 표현하는데 필요한 LLVM IR을 내보낸 다음에 LLVM을 호출하여서 LLVM IR에서 Native Code를 생성합니다.
- GPU Backend는 현재 LLVM NVPTX Backend를 통해 NVIDIA GPU를 지원하고 있으며, CPU Backend는 여러 CPU ISA를 지원합니다.
2.3. Github
-
- XLA의 Github 주소는 아래를 참고하시기 바랍니다.
3. Glow
3.0. Introduction
-
- Glow는 Machine / Deeo Learning Compiler이며 학습 Model을 가속하기 위한 Execution Engine입니다.
3.1. Conversion & Optimization

- Glow는 기존 Neural Network Dataflow Graph를 2단계 Strongly-Typed IR(Intermediate Representation)으로 변환합니다.
- High-Level IR은 Domain-Specific Optimizations수행하고, Lower-Level Instruction-Based Address-only IR은 Instruction Scheduling, Static Memory Allocation , Copy Elimination 등과 같은 메모리 관련 최적화를 수행합니다.
- Lowest Level에서는 특정 Hardware의 장점을 최대한 활용하기 위한 Machine-Specific Code를 생성합니다.
3.2. System Requirements
-
- MacOS와 Linux만 지원합니다.
- 결과물은 object file / Header File. 즉, C/C++에서만 사용가능합니다.
- 다른 Language에서 사용하려면 다소 귀찮은 작업을 해주어야 합니다.
- 조금 더 자세한 사항은 아래 Link를 참고해 주세요.
3.3. Example
-
- 실제 사용법은 아래 Link에서 자세하게 설명되어 있습니다.
보시면 아시겠지만, 여타 다른 Deep Learning Compiler와 기본적인 사용법은 크게 다르지 않습니다.
그럼, 다음에 또 만나요~!
728x90
'Deep_Learning' 카테고리의 다른 글
| LFW(Labeled Faces in the Wild) Dataset (0) | 2024.01.17 |
|---|---|
| import __future__ 구문의 의미 (2) | 2024.01.11 |
| ONNX(Open Neural Network Exchange) (2) | 2023.12.06 |
| Deep Learning Compiler (1) | 2023.12.02 |
| Jupyter Kernel 관리 - ipykernel 사용법 (0) | 2023.11.29 |