
728x90
0. Introduction
- 최근 Video Classification을 공부하는 도중 Two Stream 방식의 대표적인 Model을 사용해 보고자 마음 먹게되었습니다.
- 이번에 Review해 볼 Paper는 I3D 방식(Inflated 3D)을 제시한 것을 알아보도록 하겠습니다.
- 제목은 'Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset'이며 Link에서 확인 가능합니다.
- 실제 구현은 https://github.com/deepmind/kinetics-i3d에서 구할 수 있습니다.
1. The old ones
- 먼저 I3D가 나오기 전에 사용하던 방식들에 대해서 알아보기로 하겠습니다.
1.1. The old 1 : ConvNet + LSTM
- 기존 CNN에서 사용하던 2D ConvNet을 이용하여 Video의 각 Frame마다 Feature를 뽑아내고 이를 LSTM에 넣어서 분류하는 방법입니다.
- 기존의 잘 훈련된 Pre-Trained 2D ConvNet을 재사용 가능하다는 장점이 있지만, 시간축의 정보를 잘 훈련하지 못하는 단점이 있습니다.
- 또한, RNN의 Train이 Sequential하게 하지 못한다는 단점도 있습니다.
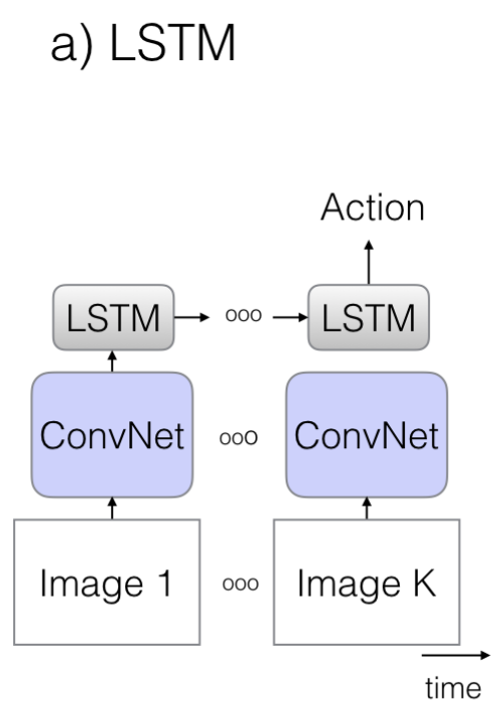
- 이 방법을 소개한 Paper들은 아래와 같습니다.
- J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2625–2634, 2015. https://arxiv.org/abs/1411.4389
- A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014. https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/42455.pdf
- Beyond Short Snippets: Deep Networks for Video Classification. Joe Yue-Hei Ng, Matthew Hausknecht, Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, George Toderici
https://arxiv.org/abs/1503.08909
1.2. The Old II: 3D ConvNets
- 2D Image가 여러장 쌓여있는 형태인 Video 분류에서 2D 대신 3D Conv를 사용하는 것은 당연한 선택이라고 생각할 수 있습니다..
- 하지만, 2D만 해도 이미 Param이 많은데, 이것을 Image 수만큼 쌓아서 Train시킨다는 것은 매우 힘들것이라는 것은 유추할 수 있습니다.
- 또한, 2D ConvNet은 훈련이 잘 된 효율적인 Model이 많지만, 3D Conv에서는 그런 것이 없습니다.
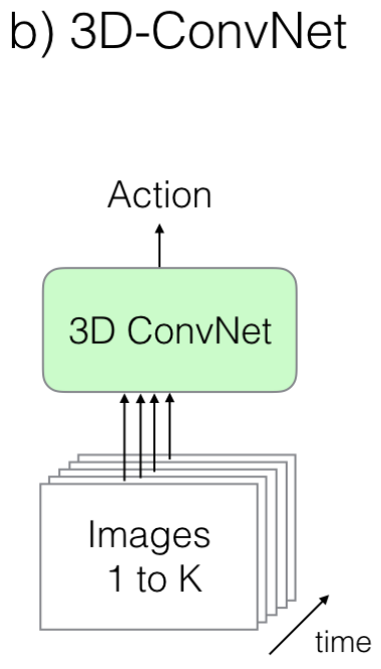
- 이 방법을 소개한 Paper들은 아래와 같습니다.
- D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. In 2015 IEEE International Conference on Computer Vision (ICCV), pages 4489–4497. IEEE, 2015
https://arxiv.org/abs/1412.0767
- D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional networks. In 2015 IEEE International Conference on Computer Vision (ICCV), pages 4489–4497. IEEE, 2015
1.3. The Old III: Two-Stream Networks - 1)
- 2D RGB Image에서 뽑은 Feature들과 함께 Optical Flow 정보도 같이( Two Stream) 넣어서 분류하는 방법
- RGB Image의 정보만으로 분류하는 것보다 확실히 훨씬 더 좋은 성능을 보여줍니다.
- Optical Flow란 이전 Image와 다음 Image의 Pixel의 얼마만큼 이동했는지 알려주는 Vector
- Video Classification에서 훌륭한 Feature가 될 수 있지만, 문제는 계산량이 매우 많다는 것이다.
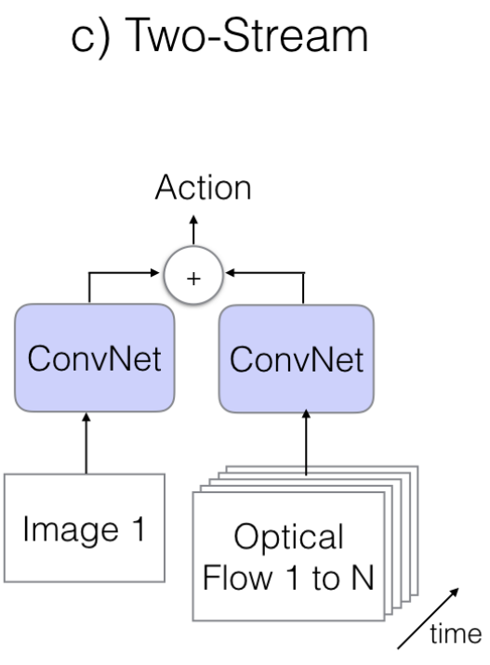
- 이 방법을 소개한 Paper들은 아래와 같습니다.
- K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems, pages 568–576, 2014 https://arxiv.org/abs/1406.2199
1.3. The Old III: Two-Stream Networks - 2)
- Two Stream방식으로 처리하지만, 앞의 방식과 다른 점은 마지막에 한 번더 3D ConvNet을 통과시킨다는 점이다.
- 성능은 큰 차이가 없지만, 연산량은 훨씬 더 늘어나게 됩니다.
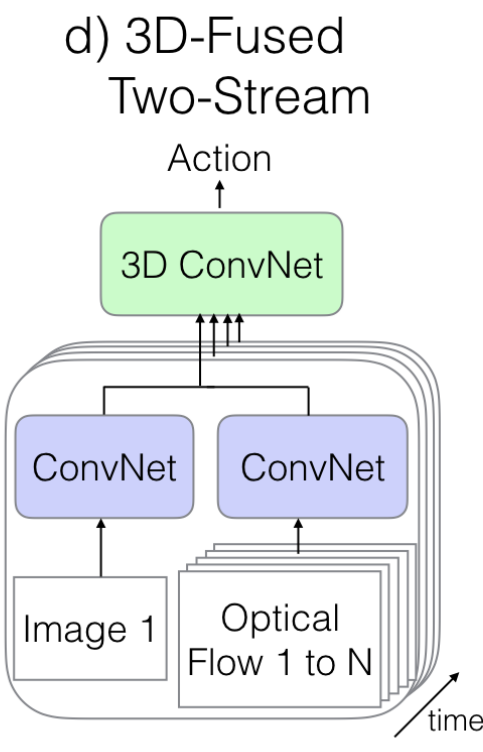
- 이 방법을 소개한 Paper들은 아래와 같습니다.
- C. Feichtenhofer, A. Pinz, and A. Zisserman. Convolutional two-stream network fusion for video action recognition. In IEEE International Conference on Computer Vision and Pattern Recognition CVPR, 2016 https://arxiv.org/abs/1604.06573
1.4. The New: Two-Stream Inflated 3D ConvNets
- 3D ConvNet의 구조를 사용하기는 하지만, 기존의 3D ConvNet과는 다른 구조로 정의해서 사용합니다.
- 기존의 잘 훈련된 2D ConvNet( 이 Paper에서는 inceptionV1을 사용)의 구조를 그대로 사용하여 성능을 올리겠다는 의도입니다.
- 2D ConvNet의 Weight를 시간 축으로 N번 쌓아올려서 3D ConvNet 구조를 만들고, 나중에 1/N으로 Scaling합니다.
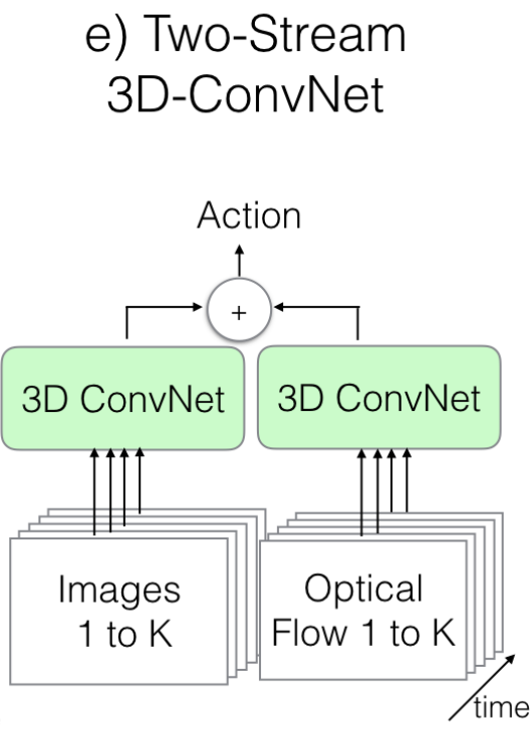
지금까지 알아본 Model들의 기본 구조 및 특징을 정리해 보면 아래와 같습니다.

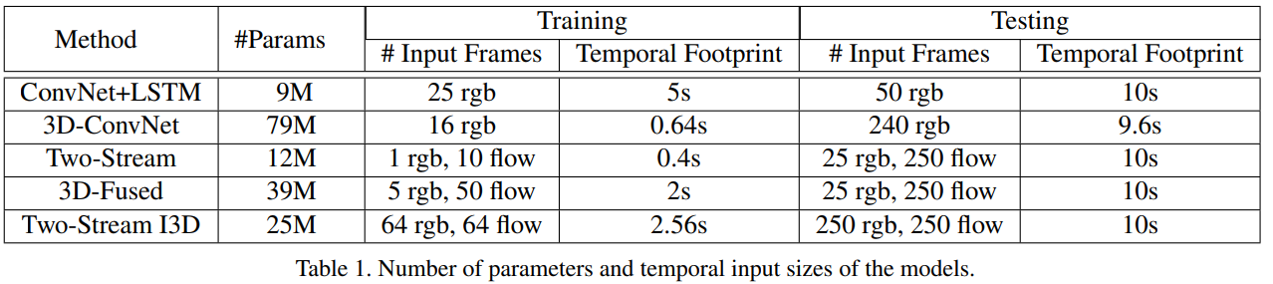
아래 표는 각 Model들의 Parameter 수와 Input Parameter들을 정리해 놓은 것입니다.
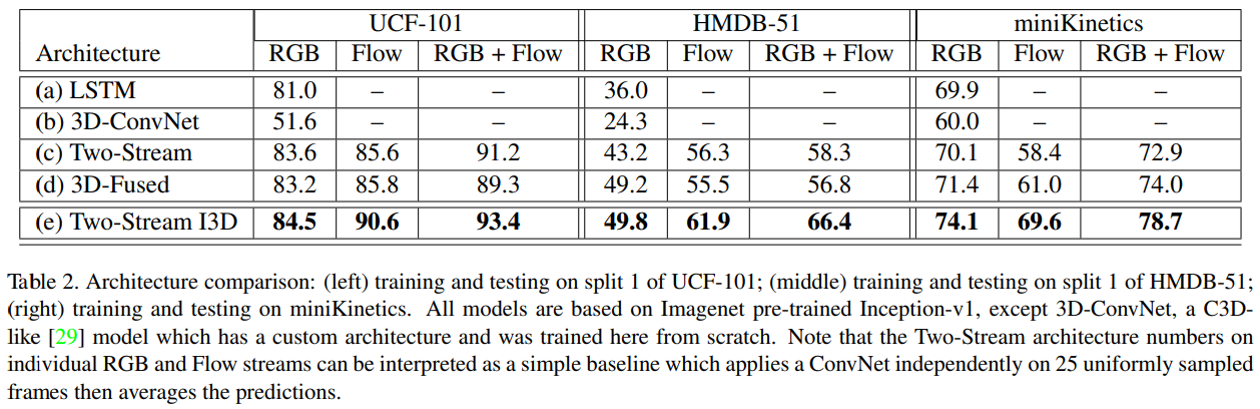
아래 표는 각 Model들의 주요 Dataset에서의 성능을 정리해 놓은 자료입니다.
2. Opinion
- 이 Paper는 2017년도에 발표되었으며, 그 당시에는 최상의 Architecture를 제안한 것이었습니다.
- 다만, 이전부터 가지고 있던 문제(?)는 Optical Flow를 사용하는 이상, Real Time으로 운영이 불가능하다는 것입니다.
- 실제로 이 Paper 이후로는 Optical Flow를 사용하지 않는 Architecture가 발표되기 시작합니다.
728x90
'Deep_Learning' 카테고리의 다른 글
| Early Stopping in Tensorflow (2) | 2023.10.04 |
|---|---|
| Deep Face Recognition - A Survey (0) | 2023.09.24 |
| A Comprehensive Study of Deep Video Action Recognition (0) | 2023.09.20 |
| Deep Learning for 3D Point Clouds: A Survey (0) | 2023.09.17 |
| Kaggle - Paddy Disease Classification (0) | 2023.09.12 |