
안녕하세요, MoonLight입니다.
Flash Attention은 Stanford 연구진에 의해 제안되었으며, 기존 Transformer 모델의 핵심 구성 요소인 Attention 메커니즘을 개선한 기술입니다.
Paper
https://arxiv.org/pdf/2307.08691
FlashAttention GitHub
https://github.com/Dao-AILab/flash-attention
GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attention
Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
github.com
0. 기존 Attention 메커니즘의 문제점
기존의 Attention 메커니즘인 Scaled Dot-Product Attention은 Transformer 모델의 핵심 요소로서, 입력 텍스트의 관련 부분에 집중하여 예측을 수행하는 데 효과가 있습니다.
이 메커니즘은 Query, Key, Value라는 세 가지 요소를 사용하여 계산하며, 수식은 비교적 간단하지만 실제 계산 과정에서는 큰 텐서들의 곱셈과 상당한 데이터 이동이 발생합니다.
특히, 시퀀스 길이가 n일 때, Attention 메커니즘은 O(n²)의 추가 메모리와 O(n²)의 계산 시간 복잡도를 가지게 됩니다. 이는 긴 시퀀스를 처리할 때 심각한 병목 현상을 발생시키며, 모델이 효과적으로 처리할 수 있는 문맥 길이를 제한하고 필요한 컴퓨팅 자원을 크게 증가시키는 원인이 됩니다.
또한, Attention 메커니즘은 Key, Query 값을 저장, 읽기, 쓰기 위해 고대역폭 메모리(HBM)를 사용하는데, 이러한 데이터를 더 빠른 온칩 SRAM으로 반복적으로 전송하는 과정은 상당한 비용을 발생시키며, GPU가 실제 연산보다 데이터 전송에 더 많은 시간을 소비하게 만드는 메모리 바운드(memory-bound) 연산을 발생시킵니다.
1. Flash Attention의 주요 특징
1.1. 속도 향상
Flash Attention은 이전 버전보다 더 빠른 연산 속도를 제공하는데, 이는 GPU 메모리 계층 구조를 더 효율적으로 활용하고, 불필요한 메모리 액세스를 줄이는 방식으로 달성됩니다.
구체적으로, 다음과 같은 기술을 사용합니다.
- Tiling : 입력 데이터를 더 작은 타일로 나누어 처리하여, GPU의 공유 메모리를 최대한 활용합니다.
- Kernel Fusion : 여러 연산을 하나의 커널로 융합하여 커널 실행 오버헤드를 줄입니다.
- Parallel Reduction : 병렬 연산을 통해 Attention 가중치를 계산하고 정규화하는 과정을 가속화합니다.
1.2. 메모리 효율성
Flash Attention은 기존 Attention 연산에 필요한 메모리 사용량을 크게 줄입니다. 이를 통해 더 긴 시퀀스를 처리하거나, 더 큰 모델을 훈련하는 것이 가능해집니다. 메모리 사용량 감소를 시키는 기법은 다음과 같은 방법이 있습니다.
- Attention 가중치 저장 최소화 : Attention 가중치를 완전히 저장하는 대신, 필요할 때마다 즉석에서 계산하여 메모리 공간을 절약합니다.
- backward pass 최적화 : 역전파 과정에서 필요한 중간 결과를 효율적으로 계산하고 저장하여 메모리 사용량을 줄입니다.
1.3. 다양한 하드웨어 지원
Flash Attention은 다양한 GPU 환경에서 잘 작동하도록 설계되었습니다. NVIDIA GPU 뿐만 아니라 AMD GPU에서도 최적의 성능을 낼 수 있도록 지원합니다.
2. Flash Attention의 동작 원리
Flash Attention의 성능 향상의 가장 큰 역할을 하는 것은 Tiling 기법과 계산시에 Global Memory(HBM, High Bandwidth Memory)를 사용하는 대신 Shared Memory를 사용하는 것, 이 2가지입니다.
2.1. Tiling
2.1.1. 기존 Attention 메커니즘의 문제점
기존의 표준 Attention 메커니즘은 다음과 같은 단계를 거칩니다.
- Query, Key, Value 생성 : 입력 시퀀스로부터 Query(Q), Key(K), Value(V) 행렬을 생성합니다.
- Attention Score 계산 : Q와 K의 내적(dot product)을 계산하여 Attention Score 행렬을 얻습니다.
- Softmax 적용 : Attention Score 행렬에 Softmax 함수를 적용하여 Attention Weight 행렬을 얻습니다.
- 가중합 계산 : Attention Weight 행렬과 V 행렬을 곱하여 최종 Attention 출력값을 얻습니다.
이 과정에서 가장 큰 문제는 2단계와 3단계에서 발생하는 큰 중간 결과물(Attention Score 및 Weight 행렬)을 GPU의 고대역폭 메모리(HBM)에 저장해야 한다는 것입니다. 시퀀스 길이가 길어질수록 이 행렬들의 크기는 제곱으로 증가하여, 메모리 병목 현상이 발생하고 속도가 느려집니다.
좀 더 자세한 Transformer의 Attention 알고리즘에 대한 내용은 아래 글을 참고해 주시기 바랍니다.
https://moonlight314.tistory.com/entry/Transformer-1-Attention-Mechanism
Transformer #1 - Attention Mechanism
0. Background Attention Mechanism이 나오기 전에는 Seq2Seq Model이 주로 사용되었습니다. Seq2Seq Model은 당시에는 훌륭한 Idea였지만, 치명적인 문제점을 가지고 있었습니다. 그 어떤 입력값이 들어
moonlight314.tistory.com
https://moonlight314.tistory.com/entry/Transformer-2-Self-Attention
Transformer #2 - Self Attention
0. Introduction 다른 글에서 Attention Mechanism에 대해서 알아보았습니다. Attention Mechanism에 대해서 자세히 알아보시려면 아래 글을 읽어보시기를 추천드립니다. https://moonlight314.tistory.com/entry/T
moonlight314.tistory.com
https://moonlight314.tistory.com/entry/Transformer-3-Overall
Transformer #3 - Overall
안녕하세요, MoonLight입니다.이번 Post에서는 Transformer의 전체 구조를 개괄적으로 알아보도록 하겠습니다. Transformer의 전체 구조의 위와 같습니다. 왼쪽이 Encoder의 구조이고, 오른쪽
moonlight314.tistory.com
https://moonlight314.tistory.com/entry/Transformer-4-Encoder-Detail
Transformer #4 - Encoder Detail
안녕하세요, 이번 Post에서는 Transformer의 Encoder에 대해서 자세히 알아보도록 하겠습니다.Transformer Encoder의 각 부분을 구체적으로 하나씩 알아보도록 하겠습니다.0. Tokenizer & Input Embedding Layer
moonlight314.tistory.com
https://moonlight314.tistory.com/entry/Transformer-5-Decoder-Detail
Transformer #5 - Decoder Detail
0. Introduction안녕하세요, 이번 Post에서는 Transformer의 Decoder에 대해서 자세히 알아보도록 하겠습니다.Transformer Decoder의 각 부분을 구체적으로 하나씩 알아보도록 하겠습니다.Encoder에
moonlight314.tistory.com
2.1.2. Tiling 기법
FlashAttention-2의 핵심은 Tiling이라는 방법인데, Tiling은 아래 그림과 같이 Q, K, V 행렬을 각각 N/B개의 블록(타일)으로 나누어서 계산하는 것입니다. 각 블록의 크기는 B x d가 되고, B는 하이퍼파라미터로 조절 가능합니다.
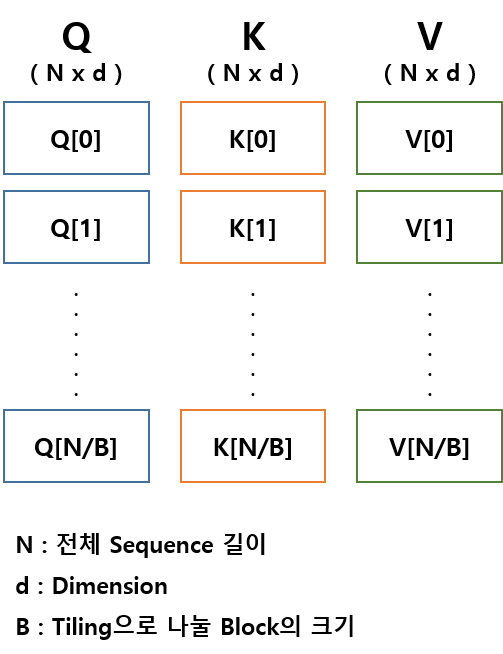
2.1.3. Tiling 기법 적용한 Attention 계산 순서
1) 블록 단위 로드
- Q, K, V의 각 블록 쌍 (Q[i], K[j], V[j])을 GPU의 빠른 공유 메모리(Shared Memory) 또는 레지스터로 로드합니다.
- HBM (High Bandwidth Memory): GPU에 장착된 고대역폭 메모리로, Global Memory라고도 불립니다. 용량이 크고 (일반적으로 수십 GB) GPU의 모든 계산 유닛(Compute Unit)이 접근할 수 있습니다. 하지만 상대적으로 속도는 느립니다.
- Shared Memory: GPU의 각 스트리밍 멀티프로세서(SM, Streaming Multiprocessor) 내부에 있는 작은 용량의 메모리입니다. (일반적으로 수십 KB ~ 수백 KB).
- 같은 SM 내의 스레드들이 빠르게 공유하고 접근할 수 있습니다. HBM (Global Memory)보다 훨씬 빠르지만 용량이 매우 작습니다.
2) 블록 단위 Attention Score 계산
- 공유 메모리 내에서 Q[i]와 K[j]의 내적을 계산하여 작은 Attention Score 블록을 얻습니다.
3) Online Softmax
- 이전 단계에서 얻은 Attention Score 블록에 대해 부분적으로 Softmax를 계산합니다. 즉, 각 블록에 대한 Softmax 통계량(최댓값, 지수 합)을 계산하고 누적합니다.
- 이 누적된 통계량을 사용하여 전체 Softmax를 근사합니다.
- Online Softmax
Online Softmax는 이 블록들을 순차적으로 처리하면서, 전체 Softmax를 근사하는 데 필요한 통계량을 점진적으로 계산하고 업데이트합니다.
즉, 타일 단위로 Softmax 연산을 수행하는 동시에, 전체 Softmax를 근사하기 위한 통계량(최댓값, 지수 합)을 점진적으로 계산하고 누적하는 방식입니다.
이를 통해 메모리 사용량을 크게 줄이면서도, 수치적으로 안정적인 Softmax 계산을 수행할 수 있습니다.
단순한 "타일별 Softmax"가 아니라, 메모리 효율성과 수치 안정성을 위한 정교한 알고리즘이라고 할 수 있습니다.
4) 블록 단위 가중합
- 부분 Softmax 결과와 V[j] 블록을 곱하여 부분적인 Attention 출력값을 얻습니다.
5) 출력 누적
- 이전 단계에서 얻은 부분 출력값을 HBM의 최종 출력 위치에 누적합니다.
6) 반복
- 모든 블록 쌍 (i, j)에 대해 1~5단계를 반복합니다.
3. Flash Attention-1 & 2 & 3 ?
Flash Attention은 현재까지 Flash Attention-3까지 발표되었습니다.
3.1. FlashAttention 1 (2022)
· Paper : FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
https://arxiv.org/abs/2205.14135
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce
arxiv.org
주요 내용
- Transformer 모델의 self-attention 연산 시 발생하는 메모리 병목 현상을 해결하기 위해 타일링(tiling) 기법을 활용하여 GPU의 고대역폭 메모리(HBM)와 온칩 SRAM 간의 데이터 이동을 최소화합니다.
- 이를 통해 정확도를 유지하면서도 메모리 효율성과 연산 속도를 향상시킵니다.
3.2. FlashAttention 2 (2023)
· 논문: FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
https://arxiv.org/abs/2307.08691
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Scaling Transformers to longer sequence lengths has been a major problem in the last several years, promising to improve performance in language modeling and high-resolution image understanding, as well as to unlock new applications in code, audio, and vid
arxiv.org
· 주요 내용
- FlashAttention 1의 한계를 보완하기 위해 워크 분할(work partitioning)과 병렬 처리(parallelism)을 개선하였습니다.
- 특히, GPU의 스레드 블록과 워프(warp) 간의 작업 분배를 최적화하여 연산 효율을 높였습니다.
- 이를 통해 이전 버전에 비해 최대 2배의 속도 향상을 달성하였습니다.
3.3. FlashAttention 3 (2024)
· 논문: FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. FlashAttention elaborated an approach to speed up attention on GPUs through minimizing memory reads/writes. Ho
arxiv.org
· 이 논문에서는 NVIDIA Hopper GPU의 새로운 기능을 활용하여 Attention 연산의 속도와 정확도를 향상시키는 세 가지 주요 기술을 소개합니다.
- 비동기성 활용: Tensor 코어와 Tensor Memory Accelerator (TMA)의 비동기성을 이용하여 계산과 데이터 이동을 겹쳐 수행합니다.
- 연산 중첩: 블록 단위의 행렬 곱셈과 소프트맥스 연산을 교차하여 실행하여 처리 속도를 높입니다.
- 저정밀도 처리: FP8과 같은 저정밀도 연산을 활용하여 성능을 향상시키며, 이를 통해 FP16 대비 최대 2배의 속도 향상을 달성합니다.
이러한 기술들을 통해 FlashAttention 3는 이전 버전에 비해 H100 GPU에서 최대 2배의 속도 향상을 이루었으며, FP8 연산 시 최대 1.2 PFLOPs/s의 성능을 달성하였습니다
4. AMD GPU Support
Flash Attention은 nVidia GPU 뿐만 아니라, AMD GPU를 사용하는 경우에도 적용이 가능합니다.
Flash Attention이 nVidia의 CUDA나 cuDNN에 종속적인 것이 아니라, 알고리즘 수준의 최적화와 Triton 프로그래밍 언어의 이식성 덕분에 다양한 GPU 환경에서 동작할 수 있습니다.
Triton은 하드웨어별 최적화를 자동으로 수행하고, Flash Attention 코드가 NVIDIA GPU와 AMD GPU 모두에서 효율적으로 실행될 수 있도록 돕습니다
5. 성능 분석
Flash Attention은 기존 Attention 메커니즘에 비해 상당한 속도 향상을 보여줍니다.
BERT-large 모델에서 15%의 엔드-투-엔드 벽시계 시간 단축을 달성했으며, GPT-2 모델에서는 기존 구현 대비 3배의 속도 향상을 보였습니다.
특히, 4K 문맥 길이를 가진 GPT-2 모델은 1K 문맥 길이를 가진 Megatron의 GPT-2 모델보다 여전히 30% 더 빠릅니다.
최신 버전인 Flash Attention 3는 Hopper GPU에서 LLM 학습 및 실행 시 이전 버전보다 1.5~2배 더 빠른 성능을 제공할 수 있습니다.
Meta의 AITemplate은 Flash Attention을 사용하여 BERT 추론 속도를 최대 5.3배까지 향상시켰고, Kernl 라이브러리는 트랜스포머 속도를 최대 12배까지 높이는 데 Flash Attention을 활용합니다.
메모리 사용량 감소 또한 Flash Attention의 중요한 이점입니다.
기존 Attention 메커니즘의 메모리 복잡도(O(N²))와 비교하여, Flash Attention은 선형적 복잡도(O(N))로 메모리 사용량을 줄입니다.
이는 GPT-2 모델에서 문맥 길이를 4배까지 늘리는 것을 가능하게 했습니다.
Hugging Face의 diffusers 라이브러리를 사용한 확산 모델에서는 Flash Attention을 통해 최대 2배 빠른 추론 속도와 더 낮은 메모리 사용량을 보였습니다.
Colossal-AI의 Stable Diffusion 구현에서는 Flash Attention을 통해 미세 조정(fine-tuning)에 필요한 하드웨어 비용을 7배나 절감했습니다.
이러한 메모리 사용량 감소는 제한된 메모리 용량을 가진 하드웨어에서 더 큰 모델을 학습하고 더 긴 시퀀스를 처리할 수 있게 하는 중요한 이점입니다.
아래 표는 Flash Attention과 기존 Attention 메커니즘의 성능 벤치마크 결과를 비교한 것입니다.
|
모델
|
측정 항목
|
기존 Attention
|
Flash Attention
|
개선율
|
|
BERT-large
|
엔드-투-엔드 속도 향상
|
1x
|
1.15x
|
15%
|
|
GPT-2
|
HuggingFace 대비 속도 향상
|
1x
|
3x
|
300%
|
|
GPT-2 (4K ctx)
|
Megatron (1K ctx) 대비 속도 향상
|
-
|
1.3x
|
30%
|
|
Stable Diff.
|
추론 속도 향상
|
1x
|
2x
|
200%
|
|
Uni-Fold
|
AlphaFold 대비 속도 향상
|
1x
|
2.6x
|
260%
|
|
OpenFold
|
AlphaFold2 대비 속도 향상
|
1x
|
3x
|
300%
|
|
PubMedGPT
|
학습 시간 감소율
|
-
|
~50% 감소
|
~2x 속도
|
|
Stable Diff.
|
미세 조정 비용 절감률
|
-
|
7x 감소
|
700% 절감
|
6. 정리
Flash Attention 기술은 기존 Attention 메커니즘의 메모리 및 계산 병목 현상을 해결함으로써 Transformer 모델의 효율성을 크게 향상시키는 혁신적인 기술입니다.
IO-Awareness, Tiling, Kernel Fusion, Recomputation과 같은 핵심 아이디어는 상당한 속도 향상과 메모리 사용량 감소를 가져와 더 큰 모델의 학습과 더 긴 시퀀스의 처리를 가능하게 합니다.
Flash Attention은 자연어 처리, 컴퓨터 비전, 계산 생물학과 같은 분야에서 대규모 트랜스포머 모델을 더욱 실용적이고 효율적으로 만들어 AI 분야 발전에 중요한 기여를 했습니다.
'Deep_Learning' 카테고리의 다른 글
| 마누스(Manus) AI Agent 사용기 (0) | 2025.04.13 |
|---|---|
| LoRA(Low-Rank Adaptation) (0) | 2025.04.12 |
| DLSS (Deep Learning Super Sampling) (0) | 2025.03.22 |
| Pandas Dataframe에 apply()에서도 진척도 확인하기 (0) | 2025.03.03 |
| Transfer Learning이란 무엇인가? (0) | 2025.02.20 |