
안녕하세요, MoonLight입니다.
Pandas의 read_csv로 CSV file을 읽거나 혹은 Text 기반의 파일을 python에서 읽으려고 할 때, "UnicodeDecodeError 'utf-8' codec can't decode byte 0x~~ in position ~ invalid start byte"라는 Error를 종종 만나곤 합니다.
대부분 한글을 포함하거나 python에서 읽을 수 없는 특수 문자들이 포함된 경우인데, 이를 해결할 수 있는 방법들에 대해서 알아보겠습니다.

1. Encoding 방식 변경
read_csv()등과 같이 File Open함수에 encoding parameter를 다른 방식으로 바꾸는 방법입니다.
df = pd.read_csv("Encoding_Error_Test.csv",encoding='utf-8')
위와 같이 utf-8로 읽으면 Error가 발생했으므로, 다른 Encoding 방식으로 변경해 봅니다.
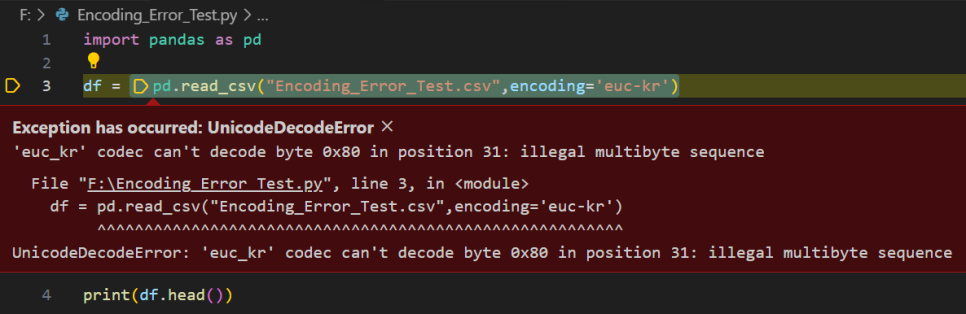
대표적으로, 'cp949'와 'euc-kr'이 있습니다.
'cp949'로 시도한 경우

'euc-kr'로 시도한 경우
2. 저장시에 Encoding 지정
간혹 위와 같이 Encoding 방식을 변경하여도 제대로 읽지 못하는 경우가 있습니다.
다음으로 시도해 볼 방법은 File을 저장할 때, Encoding 방식을 지정하는 경우입니다.
개별 Application마다 다양한 Encoding 방식을 지원하는 경우가 있기 때문에 시도해 볼만한 방법입니다.
2.1. Excel
Excel에서는 File 저장시에 Encoding방식을 변경하는 방법은 아래와 같습니다.


2.2. UltraEdit
지금까지의 방법으로도 이 문제를 해결하지 못했다면, UltraEdit로 읽은 후에 Encoding 방식을 변경 후 읽어보는 방법을 시도해 볼 수 있습니다.
아래와 같이 문제의 CSV File을 UltraEdit로 읽어들입니다.

저런 이상한 문자들때문에 읽지 못한 것 같습니다.
F12 - Save As...로 저장 준비를 한 후, 아래와 같이 UTF-8로 저장합니다.

그럼, 다시 한 번 읽어보겠습니다.

드디어 성공했습니다.
도움이 되셨기를 바랍니다. 그럼, 다음에 또 만나요~!
'Development Tip' 카테고리의 다른 글
| RuntimeError: Unexpected error from cudaGetDeviceCount() (0) | 2024.09.21 |
|---|---|
| Github Blog에서 수식 입력이 되지 않을 때 (0) | 2024.07.07 |
| No module named 'tqdm' (0) | 2024.06.12 |
| C# 고정밀도 타이머 (0) | 2024.05.14 |
| Transformer #3 - Overall (0) | 2024.04.29 |