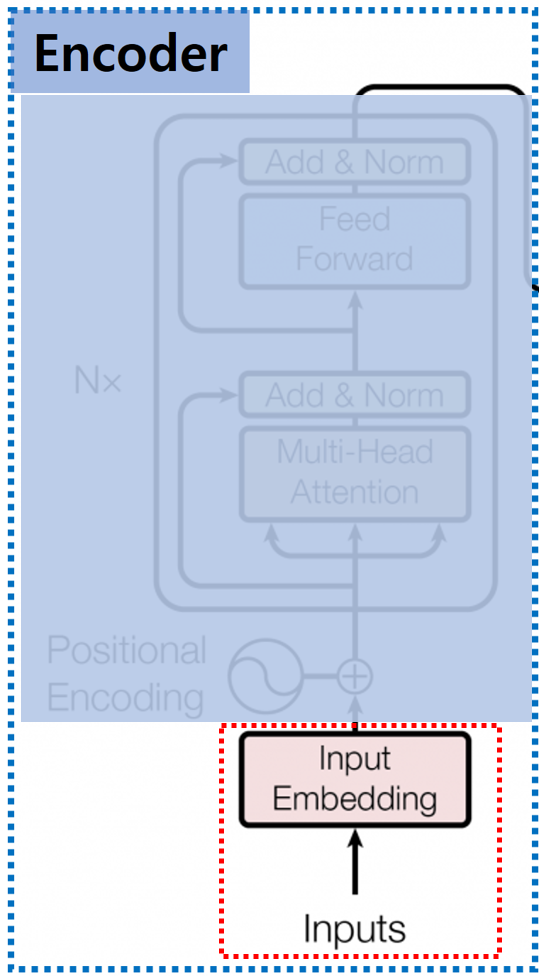
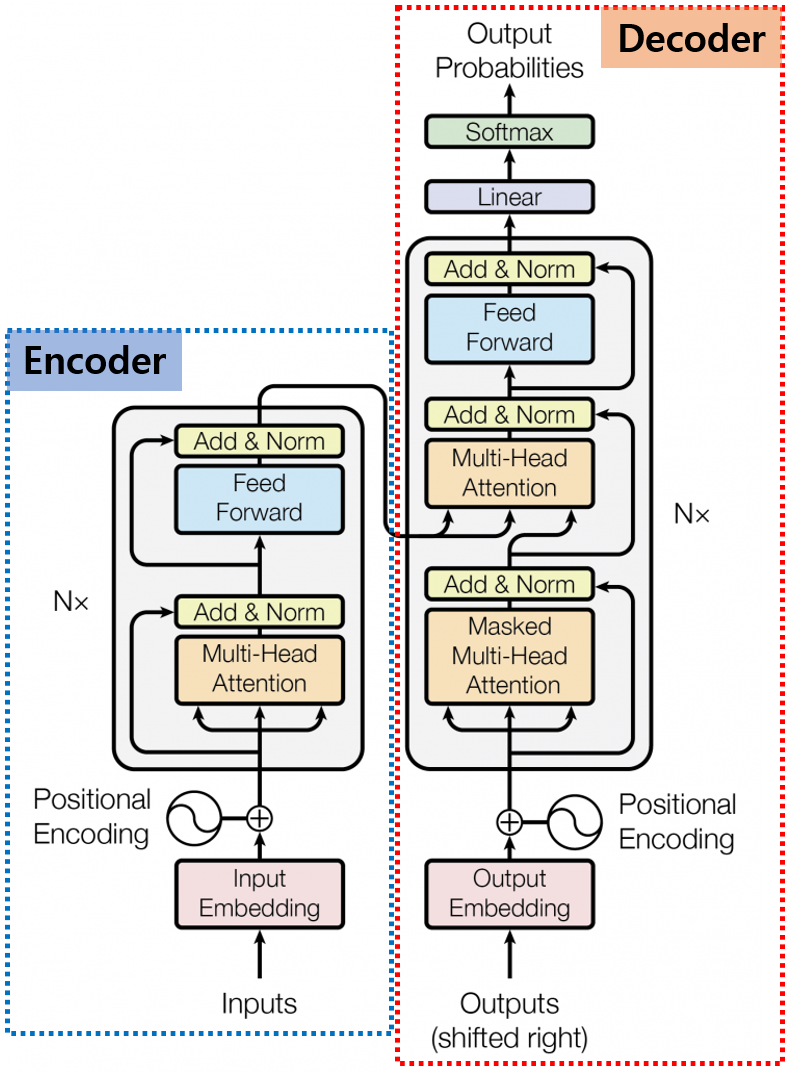
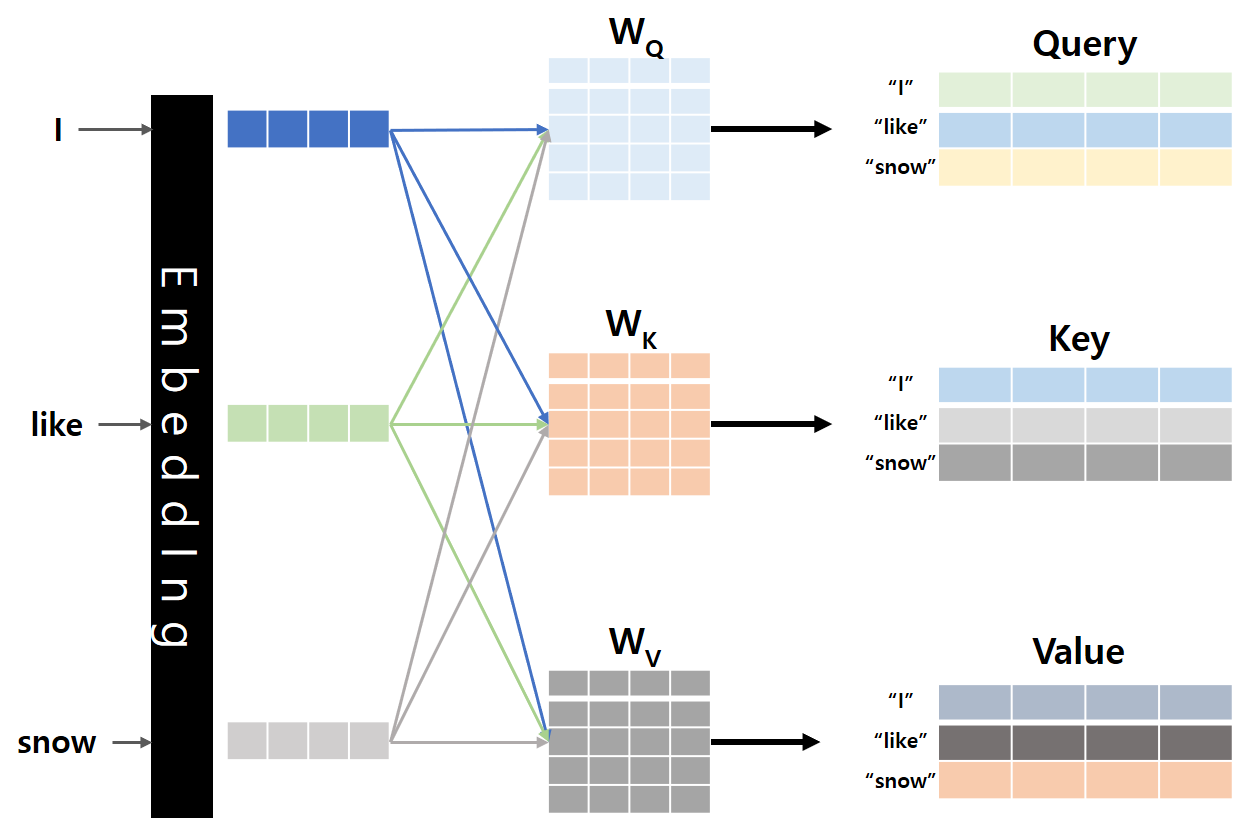
0. Introduction안녕하세요, 이번 Post에서는 Transformer의 Decoder에 대해서 자세히 알아보도록 하겠습니다.Transformer Decoder의 각 부분을 구체적으로 하나씩 알아보도록 하겠습니다.Encoder에서 살펴본 구조도 몇몇 보이지만, Decoder는 이전의 Decoder 출력을 기반으로 현재 출력을 생성해 내는 자기 회귀적 특징으로 인해 조금씩 다른 부분이 있습니다.Decoder에서 이런 자기 회귀적인 특징이 가장 많이 반영되어 있는 부분이 Masked Multi-Head Attention 부분이니 먼저 이 부분을 자세히 알아보도록 하겠습니다.1. Masked Multi-Head Attention 1.0. Shifted RightDecod..