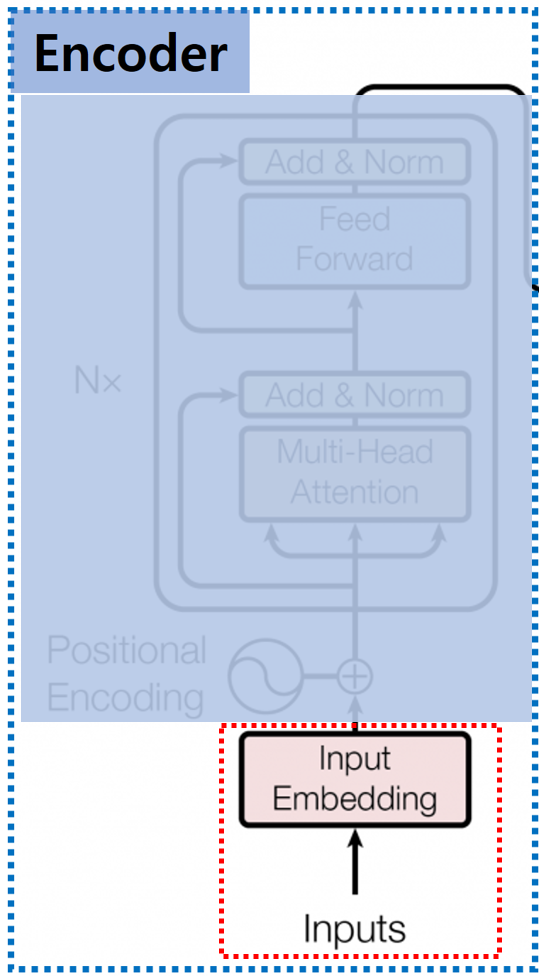
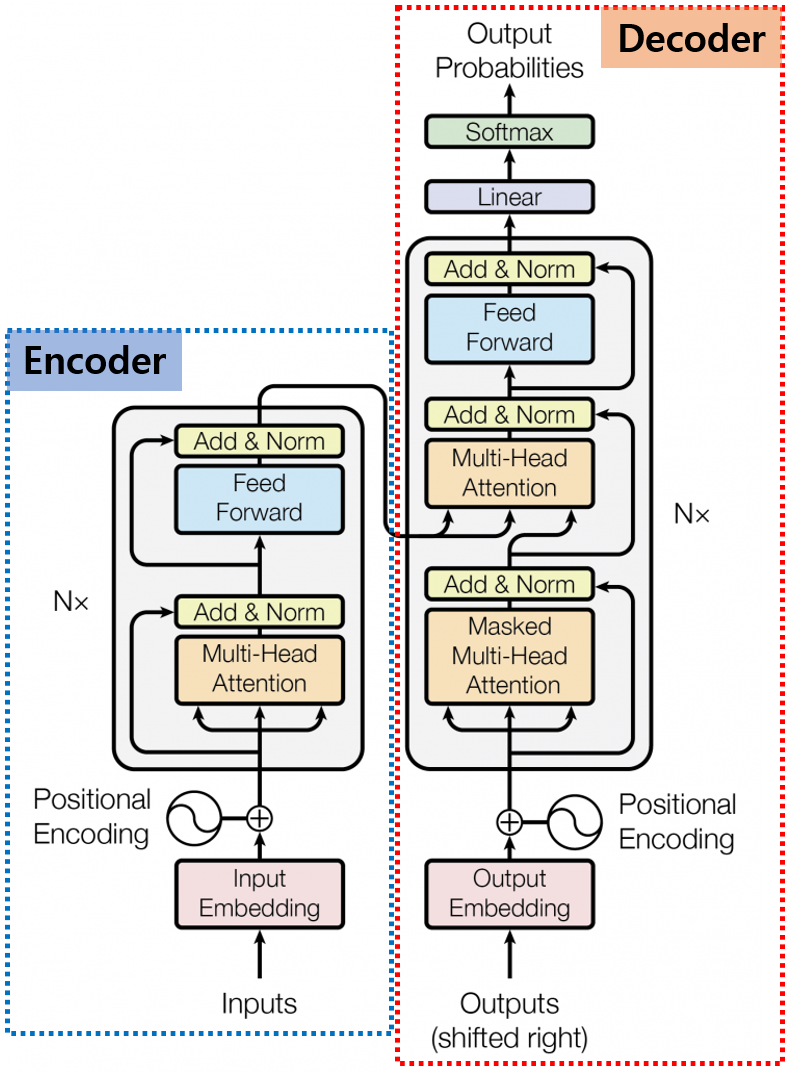
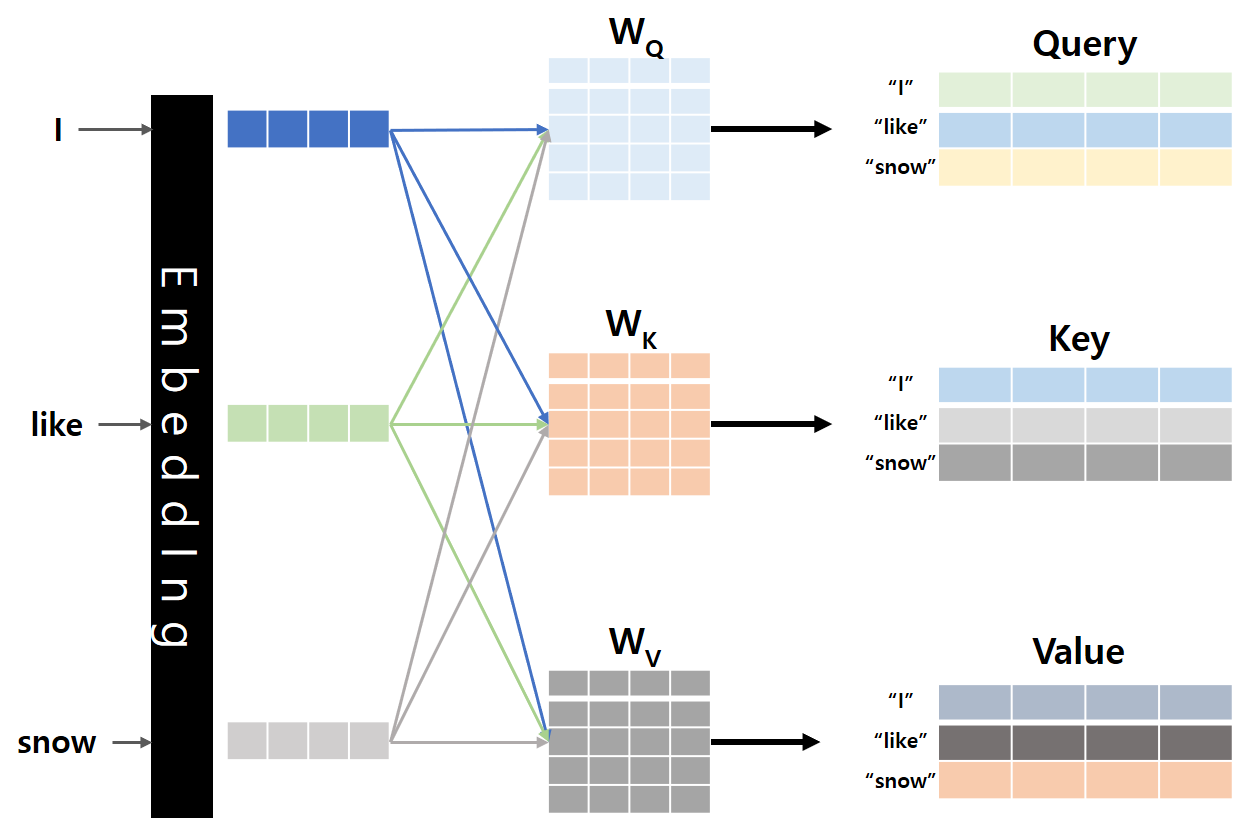
안녕하세요, MoonLight입니다.Flash Attention은 Stanford 연구진에 의해 제안되었으며, 기존 Transformer 모델의 핵심 구성 요소인 Attention 메커니즘을 개선한 기술입니다. Paperhttps://arxiv.org/pdf/2307.08691 FlashAttention GitHubhttps://github.com/Dao-AILab/flash-attention GitHub - Dao-AILab/flash-attention: Fast and memory-efficient exact attentionFast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by ..