
안녕하세요, MoonLight입니다.
지난 Post에서는 SFT(Supervised Fine-Tuning) Trainer를 사용하는 방법에 대한 내용을 다루었습니다.
https://moonlight314.tistory.com/entry/Example-of-SFTSupervised-Fine-Tuning-Trainer-in-TRL
Example of SFT(Supervised Fine-Tuning) Trainer in TRL
안녕하세요, MoonLight입니다.지난 번 Post에서 LLM을 Fine-tuning하고 Rreinforcement learning을 적용하는 데 사용되는 도구 모음인 TRL(Transformer Reinforcement Learning)에 대해서 알아보았습니다.https://moonlight314.
moonlight314.tistory.com
이번 Post에서는 TRL의 주요 Trainer 중 하나인, DPO(Direct Preference Optimization) Trainer를 사용하여 LLM Fine-Tuning을 하고 실제로 하는 방법에 대해서 알아보도록 하겠습니다.
1. Dataset 살펴보기
1.0 Overview
ultrafeedback_binarized Dataset은 주로 LLM을 인간의 선호도에 맞게 정렬(Alignment)하고 파인튜닝하기 위해 설계된 Dataset입니다.
주된 목적은 모델의 응답이 더욱 유용하고(helpful), 무해하며(harmless), 정직하도록(honest) 만드는 것이며, 이를 통해 사용자가 선호하는 답변을 생성하도록 모델을 가르칩니다.
각 데이터 Sample은 하나의 질문/프롬프트(prompt)와 그에 대한 두 가지 모델 응답(response) 쌍으로 구성됩니다.
이 두 응답 중 하나는 "chosen" (선택된, 선호되는) 응답이고, 다른 하나는 "rejected" (거부된, 덜 선호되는) 응답이며, 이 'chosen'과 'rejected' 라벨은 인간 평가자(Human Annotator)의 피드백을 바탕으로 부여됩니다.
즉, 인간이 보기에 더 좋고 적절한 응답을 'chosen'으로, 덜 좋거나 부적절한 응답을 'rejected'로 표시한 것입니다.
ultrafeedback_binarized이 다루고 있는 내용은 매우 광범위합니다.
일반적인 질문, 창의적인 글쓰기 요청, 코딩 관련 질문, 특정 시나리오에 대한 조언 요청, 사실 확인 질문, 안전 관련 질문 등 다양한 주제와 난이도를 포함하며 모델 응답 또한 다양한 LLM들이 생성한 것입니다.
ultrafeedback_binarized는 주로 RLHF (Reinforcement Learning from Human Feedback) 파이프라인의 중요한 구성 요소인 보상 모델(Reward Model) 훈련에 사용됩니다.
보상 모델은 주어진 응답의 품질을 수치로 평가하도록 학습하며, 이는 이후 강화 학습 단계에서 모델을 미세 조정하는 데 활용됩니다.
또한, 이번 Post에서 다룰 DPO (Direct Preference Optimization)와 같은 새로운 파인튜닝 방법론에도 직접적으로 사용됩니다.
DPO는 보상 모델 없이 'chosen'과 'rejected' 쌍을 사용하여 모델을 직접 파인튜닝할 수 있다는 특징이 있습니다.
1.1. 실제 Data 읽어보기
실제로 어떤 Data가 있는지 읽어보도록 하겠습니다. 아래의 Code는 'ultrafeedback_binarized' Dataset을 받아서 몇개 읽어서 보여주는 Code입니다.
from datasets import load_dataset
# 데이터셋 이름 지정
dataset_name = "trl-lib/ultrafeedback_binarized"
# 데이터셋 로드 (일반적으로 'train' 스플릿 사용)
# Hugging Face Hub에서 정확한 스플릿 이름을 확인하는 것이 좋습니다.
split_name = "train"
try:
print(f"데이터셋 '{dataset_name}'의 '{split_name}' 스플릿을 로드 중입니다...")
# ultrafeedback_binarized 데이터셋은 크기가 클 수 있습니다.
# 메모리가 부족하다면 스트리밍 모드 사용을 고려할 수 있습니다. (stream=True 옵션 추가)
dataset = load_dataset(dataset_name, split=split_name)
print(f"데이터셋 로드 완료. 총 {len(dataset)}개의 샘플이 있습니다.")
# 데이터셋의 구조(피처 또는 컬럼) 확인
print("\n--- 데이터셋 피처(컬럼) 정보 ---")
print(dataset.features)
print("-" * 30)
# 데이터셋의 첫 몇 개 샘플 출력
num_examples_to_show = 5
print(f"\n--- 첫 {num_examples_to_show}개 샘플 ---")
for i in range(min(num_examples_to_show, len(dataset))):
print(f"--- 샘플 {i+1} ---")
sample = dataset[i]
# ultrafeedback_binarized 데이터셋은 'prompt', 'chosen', 'rejected' 키를 포함합니다.
# 각 키에 해당하는 내용을 출력해 봅니다. 내용이 길 수 있으므로 일부만 출력하거나 전체를 출력할 수 있습니다.
# Prompt 출력 (전체 또는 일부)
prompt_content = sample.get('prompt', 'N/A')
print(f"Prompt:\n{prompt_content[:500]}{'...' if len(prompt_content) > 500 else ''}\n") # 프롬프트 내용 일부 출력
# Chosen 응답 출력 (일부만 출력)
chosen_content = sample.get('chosen', 'N/A')
print(f"Chosen (선택된 응답):\n{chosen_content[:500]}{'...' if len(chosen_content) > 500 else ''}\n") # Chosen 응답 일부 출력
# Rejected 응답 출력 (일부만 출력)
rejected_content = sample.get('rejected', 'N/A')
print(f"Rejected (거부된 응답):\n{rejected_content[:500]}{'...' if len(rejected_content) > 500 else ''}\n") # Rejected 응답 일부 출력
score = sample.get('score_chosen', 'N/A')
print("score_chosen : ",score)
score = sample.get('score_rejected', 'N/A')
print("score_rejected : ",score)
# 전체 샘플의 모든 필드 내용을 보려면 아래 주석을 해제하세요.
# print("--- 전체 샘플 딕셔너리 구조 ---")
# print(sample)
# print("-----------------------------")
print("-" * 30)
except Exception as e:
print(f"\n데이터셋 로드 또는 처리 중 오류 발생: {e}")
print("데이터셋 이름 또는 스플릿 이름이 올바른지 확인해주세요.")
print(f"'{dataset_name}' 데이터셋의 사용 가능한 스플릿을 확인하려면 Hugging Face Hub 페이지를 참고하세요.")
print("메모리 문제일 경우, load_dataset 함수에 stream=True 옵션을 추가하여 스트리밍 모드로 로드해보세요.")
위 코드를 실행하면, ultrafeedback_binarized Dataset의 5개 Sample을 출력해 줍니다.


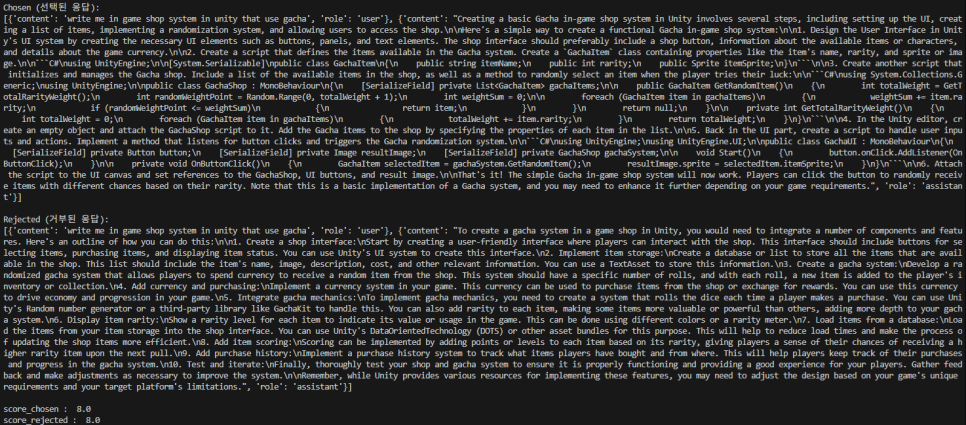
1) 구성
ultrafeedback_binarized Dataset의 주요 4개 컬럼(chosen, rejected, score_chosen, score_rejected)과 chosen/rejected 내부의 contents, role은 다음과 같은 역할을 합니다.
· 'chosen' 컬럼
인간 평가자(human annotator)가 "더 좋은" 또는 "더 선호하는" 것으로 선택한 대화 시퀀스를 담고 있으며, DPO와 같은 선호도 기반 훈련에서 모델이 학습해야 할 "정답" 또는 "긍정적인 예시"가 됩니다.
리스트 형태로 구성되어 있으며, 리스트의 각 요소는 딕셔너리입니다. 각 딕셔너리는 대화의 한 턴(turn)을 나타내며, 보통 {'role': '역할', 'content': '내용'} 형식으로 되어 있습니다.
여기서 role은 'system', 'user', 'assistant' 중 하나이며, content는 해당 역할의 발언 텍스트입니다.
· 'rejected' 컬럼
인간 평가자가 "덜 좋은" 또는 "선호하지 않는" 것으로 거부한 대화 시퀀스를 담고 있습니다.
이 rejected 대화는 chosen과 동일한 질문(프롬프트)에 대한 다른 모델의 응답이거나, 동일 모델의 다른 응답일 수 있으며, DPO와 같은 선호도 기반 훈련에서 모델이 피해야 할 "오답" 또는 "부정적인 예시"가 됩니다.
chosen 컬럼과 동일하게 딕셔너리들의 리스트 형태로 구성됩니다.
· 'score_chosen' 컬럼
chosen 응답에 대해 인간 평가자가 부여한 수치적 점수 또는 등급입니다.
보상 모델(Reward Model) 훈련 시 직접적인 정답 레이블로 사용될 수 있으며, 데이터 품질 분석이나 Dataset 필터링에 활용될 수도 있습니다.
DPO에서는 이 점수 자체를 직접적으로 사용하기보다는 chosen이 rejected보다 선호된다는 상대적인 정보가 더 중요합니다.
일반적으로 float(실수) 값으로, 높을수록 더 좋은 응답임을 나타냅니다.
· 'score_rejected' 컬럼
rejected 응답에 대해 인간 평가자가 부여한 수치적 점수 또는 등급이며, score_chosen과 동일한 목적으로 사용됩니다.
score_chosen이 score_rejected보다 높아야 의미 있는 선호도 쌍을 이룹니다.
score_chosen과 동일하게 float(실수) 값으로, 낮을수록 덜 선호되는 응답임을 나타냅니다.
chosen과 rejected는 항상 동일한 초기 질문(프롬프트)에 대한 두 가지 다른 응답 시퀀스입니다.
ultrafeedback_binarized와 같은 선호도 Dataset의 핵심 원리는 같은 입력에 대해 모델이 생성할 수 있는 여러 후보 응답들 중 인간이 더 선호하는 응답과 덜 선호하는 응답을 짝지어 주는 것입니다.
이러한 쌍을 통해 DPO와 같은 알고리즘은 모델에게 "이런 프롬프트가 주어졌을 때 chosen 응답과 같은 응답을 생성할 확률은 높이고, rejected 응답과 같은 응답을 생성할 확률은 낮춰라"라고 직접적으로 가르칩니다.
2. Train
이제 ultrafeedback_binarized Dataset과 TRL의 DPO Trainer를 이용해서 LLM을 Fine Tuning하는 예제 Code를 살펴보도록 하겠습니다.
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import DPOTrainer, DPOConfig
# 1. 선호도 데이터셋 로드 (예: trl-lib/ultrafeedback_binarized)
# DPOTrainer는 'prompt', 'chosen', 'rejected' 필드를 포함하는 데이터셋을 기대함
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train[:1%]") # 예제를 위해 일부만 사용
# 2. SFT된 모델 및 토크나이저 로드 (DPO는 SFT 모델 기반으로 시작)
model_name = "Qwen/Qwen2.5-0.5B-Instruct" # Instruct 버전 모델 사용
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 3. DPO 훈련 설정 정의 (SFTConfig와 유사하게 TrainingArguments 상속)
training_args = DPOConfig(
output_dir="./dpo_qwen_ultrafeedback",
num_train_epochs=1,
per_device_train_batch_size=2, # DPO는 쌍 데이터를 처리하므로 배치 크기 조정 필요
gradient_accumulation_steps=1,
learning_rate=1e-5, # DPO는 일반적으로 더 낮은 학습률 사용
logging_steps=10,
beta=0.1, # DPO의 핵심 하이퍼파라미터 (참조 모델과의 편차 제어)
max_prompt_length=256, # 프롬프트 최대 길이
max_length=512, # 전체 시퀀스 최대 길이
)
# 4. DPOTrainer 초기화
# ref_model=None으로 두면 trainer가 내부적으로 처리함
trainer = DPOTrainer(
model=model, # 훈련할 모델 (SFT된 모델)
ref_model=None, # 참조 모델 (None이면 자동으로 생성/관리)
args=training_args, # 훈련 설정
train_dataset=dataset, # 훈련 데이터셋 (선호도 쌍 포함)
tokenizer=tokenizer, # 토크나이저
# peft_config=lora_config, # PEFT 사용 시 설정
)
# 5. 훈련 시작
trainer.train()
# 6. (선택 사항) 훈련된 모델 저장
trainer.save_model("./dpo_qwen_ultrafeedback_final")
print("DPO 모델 훈련 및 저장이 완료되었습니다.")
Code를 실행하면 HuggingFace에서 ultrafeedback_binarized Dataset을 받습니다.

이어서 Base Model로 사용할 Qwen2.5-0.5B-Instruct도 받습니다.

Train이 시작되고 한참동안 열심히 진행됩니다.


Train이 끝났습니다.
3. Inference
Train이 끝난 Model을 사용해서 Inference를 한 번 해 보도록 하겠습니다.
Inference에 사용할 Code입니다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. 저장된 모델 및 토크나이저 경로 정의
# 훈련 스크립트에서 모델을 저장한 경로와 일치해야 합니다.
model_path = "./dpo_qwen_ultrafeedback_final"
# 2. 사용할 디바이스 설정 (GPU가 있다면 GPU 사용)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# 3. 토크나이저 로드
print(f"Loading tokenizer from {model_path}...")
tokenizer = AutoTokenizer.from_pretrained(model_path)
if tokenizer.pad_token is None:
# 훈련 스크립트에서 설정한 것과 동일하게 pad_token 설정
tokenizer.pad_token = tokenizer.eos_token
print("Setting pad_token to eos_token for the tokenizer.")
# 4. DPO 훈련된 모델 로드
print(f"Loading DPO trained model from {model_path}...")
# 모델은 AutoModelForCausalLM을 사용하여 로드합니다.
model = AutoModelForCausalLM.from_pretrained(model_path)
model.to(device) # 모델을 지정된 디바이스로 이동
model.eval() # 모델을 평가 모드로 설정 (드롭아웃 등 비활성화)
print("Model loaded successfully.")
# 5. 추론을 위한 프롬프트 준비
# Qwen-Instruct 모델은 특정 채팅 형식을 기대합니다.
# tokenizer.apply_chat_template을 사용하여 형식을 적용하는 것이 권장됩니다.
prompt_text = "Who is the Donald Trump?"
#prompt_text = "What is time zone?"
# Qwen 모델의 채팅 템플릿을 사용하여 프롬프트 형식화
# tokenize=False를 사용하여 토큰화 전에 문자열 형태로 얻습니다.
# add_generation_prompt=True는 모델이 응답을 시작하도록 지시하는 토큰을 추가합니다.
messages = [{"role": "user", "content": prompt_text}]
formatted_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print("\nFormatted Prompt for Inference:")
print(formatted_prompt)
print("-" * 20)
# 6. 프롬프트 토큰화 및 디바이스 이동
inputs = tokenizer(formatted_prompt, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
# 7. 모델 추론 (텍스트 생성)
print("Generating response...")
with torch.no_grad(): # 추론 시에는 그래디언트 계산 비활성화
# generate 메서드를 사용하여 텍스트 생성
# 다양한 생성 전략(greedy, beam search, sampling)을 사용할 수 있습니다.
# 여기서는 간단한 sampling을 사용합니다.
generated_ids = model.generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=200, # 생성할 최대 새로운 토큰 수
num_beams=1, # Beam search 크기 (1이면 greedy search)
do_sample=True, # Sampling 사용 여부
temperature=0.7, # Sampling 온도 (높을수록 다양성 증가)
top_p=0.9, # Top-p sampling 임계값
pad_token_id=tokenizer.pad_token_id # 패딩 토큰 ID 설정
)
# 8. 생성된 토큰 디코딩 및 결과 출력
# generate의 출력에는 보통 입력 프롬프트의 토큰이 포함됩니다.
# 새로 생성된 부분만 디코딩하려면 입력 토큰 길이만큼 슬라이싱합니다.
output_ids = generated_ids[0, input_ids.shape[-1]:]
response = tokenizer.decode(output_ids, skip_special_tokens=True)
print("\nGenerated Response:")
print(response)
print("\nInference test completed.")
총 2가지의 질문을 해 보았습니다.
SFT Trainer때와 마찬가지로 Donald Trump에 대해서 질문해 보았습니다.

언듯봐도 틀린 정보가 많습니다.
시간대(Time Zone)에 관한 질문도 한 번 해봤습니다.

이 대답도 틀린 내용들이 많네요.
SFT Trainer에서도 언급한 적이 있습니다만, LLM이 이와 같이 틀린 대답을 생성하는 이유는 여러가지가 있을 수 있습니다.
1) Model 크기의 한계
제가 Train에 사용한 Qwen/Qwen2.5-0.5B-Instruct Model은 5억 개의 파라미터를 가진 비교적 작은 Model입니다.
언어 Model이 세상의 복잡한 지식을 이해하고 일관되며 사실에 기반한 답변을 생성하기 위해서는 일반적으로 수십억, 또는 수천억 개의 파라미터가 필요한데, 0.5B Model은 기본적인 언어 구조나 간단한 패턴은 학습할 수 있지만, 도널드 트럼프와 같은 특정 인물에 대한 깊이 있고 정확한 정보나 복잡한 질문에 대한 상세한 답변을 생성하기에는 Model 자체의 용량(capacity)이 매우 제한적일 수 있습니다.
2) Fine Tuning Dataset (ultrafeedback_binarized)의 특성 및 정보 부족
대화 데이터는 사용자와 AI 간의 상호작용 스타일을 학습하는 데는 유용하지만, 특정 인물, 사건, 또는 전문 분야에 대한 깊이 있고 정확한 정보가 충분하지 않을 수 있습니다.
또한, Dataset이 수집된 시점 이후의 정보는 당연히 포함되어 있지 않습니다. Model이 훈련 데이터에서 도널드 트럼프에 대한 다양하고 충분한 정보를 학습하지 못했다면, 관련성 높고 사실적인 답변을 생성하기 어렵습니다.
전혀 엉뚱한 내용이 나오는 것도 훈련 데이터 자체에 포함된 어떤 이상한 패턴이나 매우 적은 빈도로 등장하는 잘못된 정보(Outlier)를 Model이 학습했을 가능성을 시사합니다.
3) 충분하지 않은 훈련 시간 (1 Epoch)
num_train_epochs=1로 설정했기 때문에 전체 Dataset에 대해 단 한 번만 학습하는 것은 Model이 새로운 데이터(ultrafeedback_binarized)의 패턴과 정보를 충분히 흡수하고 기존의 사전 학습된 지식과 잘 결합하는 데 부족할 수 있습니다.
특히 Dataset의 크기가 크거나 학습률이 너무 높지 않은 경우, 여러 Epoch를 거치며 반복 학습해야 Model이 안정적으로 수렴하고 원하는 성능을 발휘하는 경우가 많습니다.
긴 글 읽어주셔서 감사합니다.
다음에는 좀 더 유용한 정보로 돌아오겠습니다 !!
'Deep_Learning' 카테고리의 다른 글
| 주요 LLM Research #2 (0) | 2025.08.24 |
|---|---|
| 주요 LLM Research #1 (8) | 2025.08.24 |
| GPT-5 (10) | 2025.08.08 |
| RAG(Retrieval-Augmented Generation) (8) | 2025.08.06 |
| SFT Train에서의 Dataset의 변환에 관한 이야기 (9) | 2025.06.07 |