
1. 개념 및 등장배경
LLM 분야에서 관심을 받고 있는 기술 중 하나는 바로 RAG (Retrieval-Augmented Generation)입니다.
특정 기술이 주목받는다는 것은 기존 기술의 한계를 보완하고 새로운 가능성을 제시하기 때문인데, RAG가 바로 그러한 대표적인 예라고 할 수 있습니다.
ChatGPT의 등장은 전 세계적으로 대규모 언어 모델(LLM)의 시대를 활짝 열었습니다.
초기에는 사용자들의 간단한 질문에 답변하는 수준이었지만, 모델 자체의 기능이 향상되고 다양한 기능들이 추가되면서 사용자들은 점차 전문적인 영역에 대한 심도 있는 질문들을 던지기 시작했습니다.
하지만 곧 사용자들은 LLM이 가진 몇 가지 본질적인 문제점들에 직면하게 됩니다.
1) 지식 커트오프 (Knowledge Cut-off) 문제
LLM은 방대한 텍스트 데이터를 학습하지만, 훈련 데이터가 수집된 시점 이후의 최신 정보는 반영하지 못합니다.
즉, 특정 시점 이후의 사건이나 새로 발생한 지식에 대해서는 알지 못하는 '지식 커트오프' 문제를 가지고 있습니다.
이로 인해 모델이 최신 정보를 기반으로 한 질문에 정확하게 답변하지 못하거나, 심지어는 존재하지 않는 정보나 사실과 다른 내용을 마치 진실인 양 지어내는 "환각 (hallucination)" 현상을 보이기도 합니다.
2) Private 정보 활용의 한계
기업이나 개인이 보유한 민감하거나 사적인 정보(예: 회사 내부 문서, 개인 기록 등)에 대해서는 LLM이 답변할 수 없습니다.
이러한 정보를 활용하여 LLM을 사용하고 싶을 때, 단순히 문서 첨부 기능을 이용하면 해당 기밀 정보가 외부 클라우드 서비스(예: OpenAI)에 업로드되어 보안 및 개인 정보 보호 문제가 발생할 수 있습니다.
또한, 내부 데이터를 특정 방식으로 변환하여 사용하더라도, LLM이 이를 제대로 이해하고 답변하지 못하는 경우가 빈번하게 발생했습니다.
이러한 LLM의 고질적인 문제점들을 개선하고 보완하기 위해 등장한 방법론이 바로 RAG(Retrieval-Augmented Generation )입니다.
RAG는 대규모 언어 모델(LLM)에 외부 지식 검색 기능을 접목함으로써, 모델이 자신의 정적 훈련 데이터에 없는 새로운 정보도 능동적으로 탐색하고 활용하여 답변을 생성하도록 하는 기법입니다.
RAG의 핵심은 LLM이 질문에 답하기 전에 지정된 문서 집합(지식 기반, Knowledge Base)을 조회하여 질문과 관련된 최신의 신뢰성 있는 정보를 가져온 뒤, 이를 바탕으로 답변을 생성하는 것입니다.
이 과정을 통해 LLM은 특정 도메인에 특화된 정보나 최신 사실까지 반영된 정확하고 신뢰성 있는 응답을 생성할 수 있게 됩니다.
이는 마치 전문가가 자신의 방대한 지식 외에 도서관의 최신 자료를 참고하여 답변하는 것과 유사합니다.
2. 장점
1) 최신 정보 및 동적 지식 활용
RAG는 LLM이 지식 커트오프 이후의 최신 정보나 실시간으로 업데이트되는 데이터를 활용하여 답변할 수 있도록 합니다.
검색 기능을 통해 항상 최신 정보를 '검색'하여 활용하기 때문에, 모델을 재훈련할 필요 없이 지식 기반만 업데이트하면 됩니다.
2) 사적/내부 데이터 활용 가능
기업의 기밀 문서, 개인의 비공개 자료 등 private한 데이터를 바탕으로 LLM이 답변하도록 할 수 있습니다.
중요한 것은 이러한 내부 문서들을 OpenAI와 같은 외부 LLM 제공자에게 직접 업로드하는 것이 아니라, 기업 내부 또는 로컬 환경에서 데이터를 처리하고 검색한다는 점입니다.
이로 인해 민감한 정보가 외부로 유출될 위험을 최소화하면서도, 기업의 특정 도메인 지식이나 개인화된 정보에 특화된 LLM 시스템을 구축할 수 있습니다.
3) 환각 (Hallucination) 현상 감소 및 답변 신뢰도 향상
LLM이 답변한 내용의 출처를 밝히도록 함으로써, 소위 '환각' 또는 '거짓 정보 생성' 현상의 발생 빈도를 현저히 줄일 수 있습니다.
RAG 시스템은 검색된 문서 조각들을 기반으로 답변을 생성하며, 이 검색된 출처를 함께 제시할 수 있습니다.
사용자는 LLM이 제공한 답변이 어떤 정보를 근거로 하는지 명확히 확인할 수 있어 답변의 투명성과 신뢰도가 크게 향상됩니다.
4) 도메인 특화 LLM 구축 및 개인화된 챗봇 제작 가능
특정 도메인(예: 법률, 의학, 특정 기업의 고객 서비스)에 특화된 방대한 지식 기반을 활용하여 해당 분야에 대한 심도 있는 답변을 제공하는 Domain 특화 LLM을 생성할 수 있습니다.
이는 일반적인 LLM이 제공하기 어려운 전문적이고 상세한 답변을 가능하게 합니다. 나아가 개인의 특정 취향이나 생활 패턴, 과거 대화 이력 등을 학습한 지식 기반을 활용하여 고도로 개인화된 챗봇을 제작하는 것도 가능해집니다.
3. 구성 & 흐름
RAG 시스템의 전체적인 구성과 흐름을 대략적으로 알아보도록 하겠습니다.
우선 기존 LLM 시스템이 사용자의 질문에 대한 답변하는 과정입니다.

보시다시피, 사용자는 단순하게 질문을 LLM에게 Prompt를 만들어서 입력하면 LLM은 모델 내부의 학습 정보를 바탕으로 답변을 하는 Simple한 구조입니다.
이에 반해서 RAG는 아래와 같은 몇가지 추가된 과정이 있습니다.
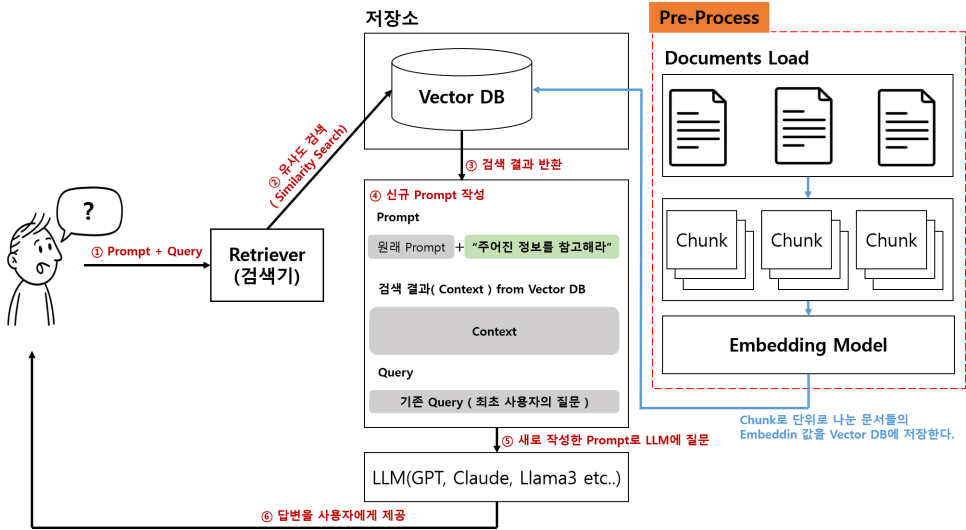
과정을 하나씩 살펴보면, 먼저 사용자가 RAG에 기존 LLM에서 하듯이 동일하게 질문을 합니다.
하지만, RAG에서는 사용자의 질문을 Retriever(검색기)에서 먼저 처리합니다.
사용자의 질문이 들어오면, RAG 시스템은 먼저 이 질문을 분석하고, 미리 구축된 외부 지식 기반(Knowledge Base)에서 가장 관련성이 높은 정보를 찾아냅니다.
이 지식 기반은 회사 내부 문서, 최신 뉴스 기사, 웹 페이지, 전문 서적 등 다양한 형태의 Document로 구성될 수 있습니다.
이 단계에서 중요한 역할을 하는 것이 임베딩(Embedding) 기술입니다.
RAG 시스템은 미리 다양한 형태로 구성된 Document들을 Chunk 단위로 나누고, 이를 각각 벡터 공간에 임베딩되어 수치화된 표현으로 변환됩니다. 이 과정을 임베딩(Embedding) 이라고 합니다.
이렇게 변환된 벡터들은 질문과 문서 간의 의미론적 유사성을 측정하는 데 사용됩니다.
일반적으로 Vector DB를 활용하여 이러한 임베딩된 문서 조각들을 저장하고, 유사도 검색을 통해 질문과 가장 유사한 문서 조각들을 효율적으로 찾아냅니다.
검색 단계에서 찾아낸 관련성 높은 문서 조각(Context)들은 사용자의 원래 질문과 함께 LLM으로 전달됩니다.
LLM은 이 추가적인 콘텍스트 정보를 바탕으로 질문에 대한 최종 답변을 생성합니다.
즉, LLM은 이제 단순히 자신의 훈련 데이터에 의존하는 것이 아니라, 외부에서 실시간으로 가져온 최신 정보를 활용하여 더욱 정확하고 관련성 높은 답변을 만들어낼 수 있게 됩니다.
이 과정에서 LLM은 검색된 정보와 자신의 내부 지식을 결합하여 답변의 품질을 향상시키고, 환각 현상을 줄이며, 정보의 출처를 명시할 수 있는 근거를 마련하게 되는 것이죠.
4. 결론
RAG는 외부 지식 기반과의 연동을 통해서 LLM의 고질적인 문제점인 지식 커트오프, 환각 현상, 그리고 사적/최신 정보 활용의 한계를 효과적으로 극복하는 접근 방식입니다.
RAG는 LLM을 단순한 대화형 AI를 넘어, 실제 비즈니스 및 개인의 삶에 깊숙이 통합될 수 있는 강력한 지능형 시스템으로 발전시키는 데 핵심적인 역할을 하고 있습니다.
'Deep_Learning' 카테고리의 다른 글
| Example of DPO(Direct Preference Optimization) Trainer in TRL (8) | 2025.08.12 |
|---|---|
| GPT-5 (10) | 2025.08.08 |
| SFT Train에서의 Dataset의 변환에 관한 이야기 (9) | 2025.06.07 |
| Example of SFT(Supervised Fine-Tuning) Trainer in TRL (2) | 2025.06.07 |
| TRL (Transformer Reinforcement Learning) (6) | 2025.06.07 |