
안녕하세요, MoonLight입니다.
이번 Post에서는 Weights & Biases (wandb)라는 Platform을 소개해 드리고자 합니다.
Weights & Biases (wandb)는 머신 러닝 실험 추적, 시각화, 협업 및 모델 관리를 위한 강력한 플랫폼입니다.
1. 소개
wandb는 2018년 Lukas Biewald, Chris Van Pelt, Shawn Lewis에 의해 설립된 Weights & Biases라는 회사에서 개발되었습니다.
이들은 머신 러닝 엔지니어들이 겪는 실험 관리의 어려움을 해결하고자 이 플랫폼을 만들었다고 하네요.
wandb는 LLM(Large Language Model) 파인 튜닝과 같이 복잡하고 리소스 집약적인 머신 러닝 프로젝트뿐만 아니라, 일반적인 딥러닝 모델 훈련에서도 매우 강력하고 유용한 도구입니다.
2. 기능
2.1. 실험 추적 (Experiment Tracking)
1) 자동 Logging
PyTorch, TensorFlow, Keras, JAX 등 딥러닝 프레임워크에 상관없이 wandb.init()을 Code에 추가함으로써 기본적인 정보(하이퍼파라미터, 지표 등)를 자동으로 로깅합니다.
wandb.config를 사용할 경우에는 훈련에 사용된 모든 하이퍼파라미터(learning rate, batch size, optimizer 종류, 모델 아키텍처 설정 등)를 체계적으로 기록합니다.
뿐만 아니라, 훈련 중에 하이퍼파라미터를 변경하는 경우(예: learning rate scheduling), 변경된 값을 추적합니다.
2) 지표 로깅
Train 중에 훈련 손실(training loss), 검증 손실(validation loss), 정확도(accuracy), F1-score, AUC, precision, recall 등 다양한 성능 지표를 추적하는 기능이 있습니다.
많이 쓰이는 Metrics뿐만 아니라, Custom Metrics도 정의하고 로깅할 수 있습니다.
또한, GPU/CPU 사용률, 메모리 사용량, 전력 소비량, 네트워크 트래픽을 추적하여 데이터 로딩 병목 현상을 파악할 수 있으며, 필요한 경우 사용자 정의 시스템 지표를 추가할 수 있습니다.
3) 코드 버전 관리
Git 저장소와 연동하여 실험에 사용된 코드 버전을 자동으로 추적하는 기능도 제공합니다.
훈련 스크립트, 모델 정의 파일 등 코드 파일을 wandb에 직접 저장하여 완벽한 재현성을 보장하며, 코드 변경 사항을 시각적으로 비교하여 어떤 변화가 실험 결과에 영향을 미쳤는지 파악하는 것도 가능합니다.
4) 데이터셋 버전 관리
훈련, 검증, 테스트 데이터셋을 버전 관리하고, 실험 간에 데이터셋을 비교할 수 있으며, 데이터셋의 샘플을 시각화하여 데이터의 분포, 이상치 등을 확인할 수 있는 기능도 제공합니다.
2.2. 시각화 (Visualization)
1) 대화형 차트
시간/스텝에 따른 지표 변화, 여러 실험의 하이퍼파라미터와 성능 지표 간의 관계, 여러 실험의 성능 지표, 데이터 분포, 분류 모델의 성능, 하이퍼파라미터, 지표 등을 각 값들의 성격에 맞는 그래프 종류를 이용하여 시각화하여 보여줍니다.
2) 커스텀 대시보드
그래프들의 구성을 드래그 앤 드롭 방식으로 원한는 대로 배치할 수 있습니다.
또한, 자주 사용하는대시보드 레이아웃을 템플릿으로 저장하여 재사용할 수 있으며, 대시보드의 공개 여부도 선택할 수 있습니다.
3) 미디어 로깅 & 시각화
Train 중의 모델의 중간 결과를 시각화하여 보여주는 기능이 있습니다.
이미지 분류 모델이라면 중간 결과를 출력하여 어떤 이미지를 분류를 잘 하고 있는지 혹은 어떤 이미지를 분류를 잘 못하고 있는지 등을 시각화해줍니다.
이미지 분류 모델뿐 아니라, Audio, Video, 3D Object 등도 적절하게 시각화하는 기능을 제공합니다.
2.3. 협업 (Collaboration)
1) 프로젝트 공유
팀원들과 함께 프로젝트를 공유하고 실험 결과를 실시간으로 확인할 수 있으며, 팀원들에게 역할(viewer, editor, admin)을 부여하여 접근 권한을 제어할 수도 있습니다.
2) 보고서 생성
차트, 표, 텍스트 등을 이용하여 실험 결과를 요약한 보고서를 자동으로 생성하여 공유할 수 있습니다.
3) 토론 및 주석
실험 결과에 대한 다양한 의견을 댓글 형태로 남길 수 있으며, 특정 댓글을 강조할 수도 있습니다.
2.4. 자동화 (Automation)
1) Hyperparameter Sweeps
Train에 중요한 영향을 미치는 하이퍼파라미터를 다양한 조합으로 실험하여 최적의 조건을 찾아주는 기능입니다.
하이퍼파라미터를 선택하는 방법으로는 Grid Search, Random Search, Bayesian Optimization 등의 다양한 탐색 전략을 지원합니다.
또한, 동시에 여러 실험을 실행하여 탐색 속도를 높일 수도 있습니다.
2) Alerts
특정 지표가 임계값을 넘거나 실험이 실패했거나 이상 징후를 감지하면 이메일 등 다양한 방법으로 알림을 받을 수 있습니다.
3) Integrations
AWS, GCP, Azure 등이나 Kubernetes, Slurm, Kubeflow, MLflow 등과 같은 다양한 도구나 클라우드 플랫폼과 연동하여 사용할 수 있습니다.
3. Example
wandb에는 다양한 기능이 있지만, 가장 활용도가 높을 것 같은 Logging 기능과 Sweep 기능을 실제로 사용해 보도록 하겠습니다.
3.1. Log-in & API Key
Weights & Biases: The AI Developer Platform
Weights & Biases is the leading AI developer platform to train and fine-tune models, manage models from experimentation to production, and track and evaluate GenAI applications powered by LLMs.
wandb.ai

다양한 방법이 있으니, 편하신 방법으로 Login하면 됩니다.
Login한 상태에서 Code상에서 wandb.init()을 호출하거나 CLI에서 wandb login 명령어를 직접 실행하여 로그인할 수도 있습니다.
실행하면 터미널에 wandb에 로그인하라는 메시지와 함께 웹사이트 링크가 표시됩니다. 해당 링크를 통해 로그인하면 API Key가 발급되고, 이를 터미널에 붙여넣거나 자동으로 인증이 완료됩니다.
API Key는 우리의 Code가 wandb 서버에 데이터를 전송할 때, 우리 계정으로 인증하기 위한 비밀 토큰입니다.
이 키가 있어야 wandb는 어떤 사용자의 실험인지 식별하고 해당 계정에 데이터를 저장할 수 있습니다.
다시 확인하고 싶으신 경우에는 wandb Site에서 계정을 누르면 'User Settings' - 'API Keys' 항목에서 확인할 수 있습니다.
추후에 Code상으로 wandb를 사용하는 경우에 API Key는 꼭 필요하니 잘 확인해 두시기 바랍니다.
3.2. 지표 Logging
아래 Train Code는 Torch로 작성한 Cat & Dog 분류 Model Train Code입니다.
이 Code에 wandb의 지표 Logging 기능을 적용해 보도록 하겠습니다.
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.models import efficientnet_b0
from torch.utils.data import Dataset, DataLoader, Subset
from PIL import Image
import glob
from sklearn.model_selection import train_test_split
BATCH_SIZE = 512
# 1️⃣ Dataset 정의
class DogCatDataset(Dataset):
def __init__(self, image_dir, transform=None):
self.image_dir = image_dir+"\\**\\*.jpg"
self.image_filenames = glob.glob(self.image_dir, recursive=True)
self.transform = transform
# 클래스 라벨 할당 (Dog: 0, Cat: 1)
self.labels = [0 if "dog" in filename else 1 for filename in self.image_filenames]
def __getitem__(self, index):
img_path = self.image_filenames[index]
image = Image.open(img_path).convert("RGB")
label = self.labels[index] # Dog(0), Cat(1)
if self.transform:
image = self.transform(image)
return image, label
def __len__(self):
return len(self.image_filenames)
# 2️⃣ 데이터 전처리 및 Train / Validation 분리
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
dataset = DogCatDataset(".\\Cat_Dog\\training_set\\training_set", transform=transform)
# 이미지 경로와 라벨 리스트 추출
indices = list(range(len(dataset)))
labels = dataset.labels # 각 이미지의 라벨 리스트 (0: Dog, 1: Cat)
# Stratified Train/Validation Split (80% Train, 20% Validation)
train_indices, val_indices = train_test_split(indices, test_size=0.2, stratify=labels, random_state=42)
# Subset을 이용해 Train / Validation Dataset 생성
train_dataset = Subset(dataset, train_indices)
val_dataset = Subset(dataset, val_indices)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 3️⃣ 모델 정의 (Pretrained ResNet18 사용)
class DogCatClassifier(nn.Module):
def __init__(self):
super(DogCatClassifier, self).__init__()
self.model = efficientnet_b0(pretrained=True)
self.model.fc = nn.Linear(512, 2) # Output layer 수정 (2 classes)
def forward(self, x):
return self.model(x)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = DogCatClassifier().to(device)
# 4️⃣ 손실 함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 5️⃣ 학습 및 검증 루프
num_epochs = 10
for epoch in range(num_epochs):
model.train()
total_train_loss = 0.0
correct_train, total_train = 0, 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_train_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
# 검증 단계 (Validation)
model.eval()
total_val_loss = 0.0
correct_val, total_val = 0, 0
with torch.no_grad():
for val_images, val_labels in val_loader:
val_images, val_labels = val_images.to(device), val_labels.to(device)
val_outputs = model(val_images)
val_loss = criterion(val_outputs, val_labels)
total_val_loss += val_loss.item()
_, val_predicted = torch.max(val_outputs, 1)
total_val += val_labels.size(0)
correct_val += (val_predicted == val_labels).sum().item()
train_loss = total_train_loss / len(train_loader)
train_acc = 100 * correct_train / total_train
val_loss = total_val_loss / len(val_loader)
val_acc = 100 * correct_val / total_val
print(f"Epoch [{epoch+1}/{num_epochs}], "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, "
f"Validation Loss: {val_loss:.4f}, Validation Acc: {val_acc:.2f}%")
print("Training Completed!")
아래 wandb를 적용한 Code를 살펴보겠습니다.
기존과 다른 부분만 살펴보겠습니다.
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.models import efficientnet_b0 # efficientnet_b0 임포트 확인
from torch.utils.data import Dataset, DataLoader, Subset
from PIL import Image
import glob
from sklearn.model_selection import train_test_split
import wandb #⭐️ wandb 임포트
import wandb
: wandb 라이브러리를 임포트합니다.
# --- 하이퍼파라미터 설정 ---
# wandb.config 에서 관리하도록 값들을 정의합니다.
config_defaults = {
'batch_size': 512, # BATCH_SIZE (필요시 조정)
'learning_rate': 0.001,
'epochs': 10,
'optimizer': 'Adam',
'architecture': 'EfficientNet-B0',
'image_size': 128,
'random_seed': 42,
'dataset_path': ".\\Cat_Dog\\training_set\\training_set" # 데이터셋 경로도 config로 관리
}
wandb.init에 사용할 Hyperparameter들을 미리 Dict.형태로 설정합니다.
# ⭐️ 1. wandb 초기화
wandb.init(
project="dog-cat-classification-teaching", # wandb 프로젝트 이름 (자유롭게 설정)
entity="moonlight314-hlds", # 👈 본인의 wandb 사용자 이름 또는 팀 이름으로 변경하세요!
config=config_defaults # 하이퍼파라미터 설정 전달
)wandb: Using wandb-core as the SDK backend. Please refer to https://wandb.me/wandb-core for more information.
wandb: Currently logged in as: moonlight314 (moonlight314-hlds) to https://api.wandb.ai. Use `wandb login --relogin` to force relogin
wandb.init()
: 스크립트 시작 부분에서 호출하여 wandb 실행(run)을 초기화합니다.
- project : 이 실험이 속할 프로젝트 이름을 지정합니다. wandb 대시보드에서 이 이름으로 프로젝트가 생성됩니다.
- entity : 본인의 wandb 사용자 이름(username) 또는 팀 이름(team name)으로 변경해야 합니다. 이걸 설정해야 본인 계정에 실험 결과가 기록됩니다.
- config : 미리 작성된 훈련에 사용될 Hyperparameter를 Dict.형태로 전달합니다. 이렇게 하면 wandb 대시보드에서 각 실험에 사용된 하이퍼파라미터를 쉽게 확인하고 비교할 수 있습니다. 코드 내에서도 wandb.config 객체를 통해 이 값들을 일관되게 사용합니다. (config.batch_size, config.learning_rate 등)
# ⭐️ wandb.config 객체를 통해 하이퍼파라미터 접근
config = wandb.config# --- 데이터 전처리 및 Train / Validation 분리 ---
transform = transforms.Compose([
transforms.Resize((config.image_size, config.image_size)), # ⭐️ config 사용
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # ImageNet 표준 정규화 사용 권장
])
Data 전처리 부분에서도 Config.의 설정을 사용해야 하는 부분은 wandb에서 설정한 Config.값을 이용합니다.
try:
dataset = DogCatDataset(config.dataset_path, transform=transform) # ⭐️ config 사용
print(f"Dataset loaded: {len(dataset)} images found.")
if len(dataset) == 0:
raise ValueError("Dataset is empty. Check the dataset_path and image files.")
indices = list(range(len(dataset)))
labels = dataset.labels
train_indices, val_indices = train_test_split(indices, test_size=0.2, stratify=labels, random_state=config.random_seed) # ⭐️ config 사용
train_dataset = Subset(dataset, train_indices)
val_dataset = Subset(dataset, val_indices)
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=config.batch_size, shuffle=False)
print(f"Train dataset size: {len(train_dataset)}")
print(f"Validation dataset size: {len(val_dataset)}")
except Exception as e:
print(f"Error during data loading or splitting: {e}")
wandb.finish(exit_code=1) # 오류 발생 시 wandb 종료
exit() # 프로그램 종료Dataset loaded: 8005 images found.
Train dataset size: 6404
Validation dataset size: 1601
# --- 모델 정의 ---
class DogCatClassifier(nn.Module):
def __init__(self, num_classes=2):
super(DogCatClassifier, self).__init__()
# efficientnet_b0 모델 로드 (pretrained=True 권장)
self.model = efficientnet_b0(weights='EfficientNet_B0_Weights.DEFAULT') # 최신 방식으로 weights 로드
# EfficientNet-B0의 classifier는 마지막 Linear 레이어입니다.
# 입력 피처 수는 1280입니다. (ResNet18은 512)
num_ftrs = self.model.classifier[1].in_features
self.model.classifier[1] = nn.Linear(num_ftrs, num_classes)
def forward(self, x):
return self.model(x)
model = DogCatClassifier(num_classes=2).to(device)
# ⭐️ 2. 모델 구조 및 그래디언트 추적 (선택 사항이지만 유용)
# 학습 시작 전에 호출해야 합니다. log='all'은 그래디언트와 파라미터 모두 로깅
wandb.watch(model, log='all', log_freq=100) # 100 스텝마다 로깅
wandb.watch(model, ...)
-
- 모델 객체를 전달하여 모델의 그래디언트 변화와 파라미터 분포를 추적합니다.
- 디버깅이나 모델 구조 확인에 도움이 됩니다.
- log_freq : 몇 스텝(배치)마다 로깅할지 지정합니다. 너무 자주하면 약간의 오버헤드가 발생할 수 있습니다.(선택 사항이지만 유용)
# 옵티마이저도 config에 따라 설정 가능
if config.optimizer == "Adam":
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate) # ⭐️ config 사용
elif config.optimizer == "SGD":
optimizer = optim.SGD(model.parameters(), lr=config.learning_rate, momentum=0.9) # 예시
else:
# 기본값 또는 오류 처리
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)# --- 학습 및 검증 루프 ---
print("Starting training...")
for epoch in range(config.epochs): # ⭐️ config 사용
# --- Training Phase ---
model.train()
total_train_loss = 0.0
correct_train, total_train = 0, 0
for batch_idx, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
# ⭐️ 3. 배치 레벨 로깅 (선택 사항, 너무 자주하면 성능 저하 가능)
if batch_idx % 10 == 0: # 10 배치마다 로깅 (예시)
wandb.log({
"batch_loss": loss.item(),
"step": epoch * len(train_loader) + batch_idx # 전체 스텝 기준
})
# --- Validation Phase ---
model.eval()
total_val_loss = 0.0
correct_val, total_val = 0, 0
val_image_log_list = [] # 검증 이미지 로깅을 위한 리스트
with torch.no_grad():
for batch_idx_val, (val_images, val_labels) in enumerate(val_loader):
val_images, val_labels = val_images.to(device), val_labels.to(device)
val_outputs = model(val_images)
val_loss = criterion(val_outputs, val_labels)
total_val_loss += val_loss.item()
_, val_predicted = torch.max(val_outputs.data, 1)
total_val += val_labels.size(0)
correct_val += (val_predicted == val_labels).sum().item()
# ⭐️ 4. 검증 이미지 및 예측 결과 로깅 (마지막 배치만 또는 일부만)
if batch_idx_val == len(val_loader) - 1: # 마지막 배치만 로깅 (예시)
# 최대 16개의 이미지만 로깅 (wandb 성능 고려)
num_images_to_log = min(val_images.size(0), 16)
for i in range(num_images_to_log):
image = val_images[i].cpu() # CPU로 이동
predicted_label = val_predicted[i].item()
true_label = val_labels[i].item()
caption = f"Pred: {'Cat' if predicted_label == 1 else 'Dog'}, True: {'Cat' if true_label == 1 else 'Dog'}"
val_image_log_list.append(wandb.Image(image, caption=caption))
# --- 에폭별 평균 계산 ---
avg_train_loss = total_train_loss / len(train_loader)
train_acc = 100. * correct_train / total_train
avg_val_loss = total_val_loss / len(val_loader)
val_acc = 100. * correct_val / total_val
# ⭐️ 5. 에폭 레벨 지표 로깅
log_dict = {
"epoch": epoch + 1,
"train_loss": avg_train_loss,
"train_accuracy": train_acc,
"val_loss": avg_val_loss,
"val_accuracy": val_acc,
}
# 검증 이미지 로그가 있으면 추가 (매 에폭마다 추가하면 너무 많을 수 있으므로 조건부 추가 가능)
if val_image_log_list:
log_dict["validation_examples"] = val_image_log_list
wandb.log(log_dict)
# 콘솔 출력 (기존과 동일)
print(f"Epoch [{epoch+1}/{config.epochs}], "
f"Train Loss: {avg_train_loss:.4f}, Train Acc: {train_acc:.2f}%, "
f"Val Loss: {avg_val_loss:.4f}, Val Acc: {val_acc:.2f}%")
print("Training Completed!")
wandb.log({...})
- 배치 레벨 로깅 (선택 사항)
- 훈련 루프 내에서 loss.item() 등을 로깅하여 더 세밀한 변화를 볼 수 있습니다.
- 하지만 너무 자주 로깅하면 I/O 부하가 커질 수 있으므로, if batch_idx % N == 0: 와 같이 N 배치마다 로깅하는 것이 좋습니다.
- 전체 스텝 수를 함께 로깅하면 x축을 스텝 기준으로 볼 수 있습니다.
- 에폭 레벨 로깅
- 한 에폭의 훈련과 검증이 끝난 후, 평균 손실(loss)과 정확도(accuracy) 같은 주요 지표들을 로깅합니다.
- 이것이 가장 일반적인 로깅 방식입니다.
- epoch 번호를 함께 로깅하면 wandb 대시보드에서 에폭별 변화 추이를 쉽게 볼 수 있습니다.
- 이미지 로깅 (wandb.Image)
- 검증 단계에서 일부 이미지와 모델의 예측 결과를 wandb.Image 객체로 만들어 로깅할 수 있습니다.
- 대시보드에서 이미지를 직접 보면서 모델이 어떤 실수를 하는지 직관적으로 파악하는 데 매우 유용합니다.
- 모든 이미지를 로깅하면 부담이 크므로, 일부 샘플만 (예: 마지막 배치 또는 랜덤 샘플) 로깅하는 것이 좋습니다.
Starting training...
Epoch [1/10], Train Loss: 0.2342, Train Acc: 89.23%, Val Loss: 0.1447, Val Acc: 96.94%
Epoch [2/10], Train Loss: 0.0457, Train Acc: 98.39%, Val Loss: 0.1250, Val Acc: 97.38%
Epoch [3/10], Train Loss: 0.0247, Train Acc: 99.22%, Val Loss: 0.1136, Val Acc: 97.13%
Epoch [4/10], Train Loss: 0.0155, Train Acc: 99.52%, Val Loss: 0.1006, Val Acc: 97.19%
Epoch [5/10], Train Loss: 0.0103, Train Acc: 99.64%, Val Loss: 0.0806, Val Acc: 97.69%
Epoch [6/10], Train Loss: 0.0077, Train Acc: 99.75%, Val Loss: 0.0733, Val Acc: 97.88%
Epoch [7/10], Train Loss: 0.0129, Train Acc: 99.67%, Val Loss: 0.1008, Val Acc: 97.31%
Epoch [8/10], Train Loss: 0.0078, Train Acc: 99.75%, Val Loss: 0.1108, Val Acc: 96.63%
Epoch [9/10], Train Loss: 0.0129, Train Acc: 99.56%, Val Loss: 0.0908, Val Acc: 96.88%
Epoch [10/10], Train Loss: 0.0131, Train Acc: 99.53%, Val Loss: 0.0904, Val Acc: 97.31%
Training Completed!# ⭐️ 6. 학습 완료 후 wandb 종료
wandb.finish()
wandb.finish()
-
- 모든 훈련이 끝나면 호출하여 wandb 실행을 정상적으로 종료하고 모든 데이터가 서버로 전송되도록 합니다.
Train이 종료가 되면, 마지막에 결과 Report를 볼 수 있는 Link를 보여줍니다.
이 Link에 들어가보면 Logging한 값들이 Step별로 볼 수도 있는 Report가 있습니다.
먼저, 아래는 각 Metric을 Step별로 변화추세를 보여줍니다.
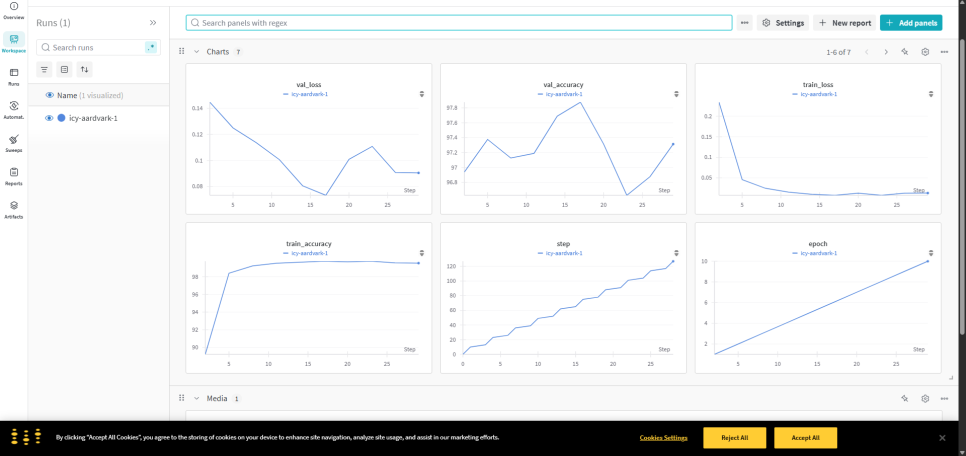
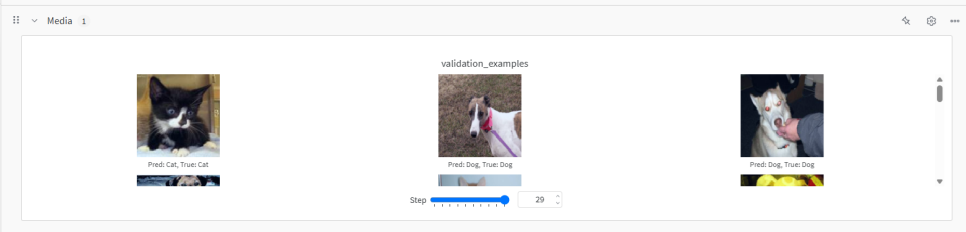
그 아래에는 Media라는 항목이 있는데, 코드에서 wandb.log({"validation_examples": val_image_log_list}) 부분에서 로깅한 검증 데이터셋(Validation data)의 샘플 이미지들을 보여줍니다.
각 이미지 아래에는 코드에서 설정한 caption (예: "Pred: Cat, True: Cat")이 표시되어, 모델의 예측(Pred)과 실제 정답(True)을 시각적으로 비교할 수 있습니다.
모델이 어떤 종류의 이미지를 잘 맞추고, 어떤 이미지를 헷갈려 하는지 직관적으로 파악하는 데 매우 유용합니다.
Gradients와 Parameter항목은 wandb.watch(model, ...) 기능을 통해 자동으로 생성됩니다.
모델 내부의 가중치(Weight)와 편향(Bias) 값, 그리고 역전파 시 계산되는 그래디언트(Gradient) 값들의 분포(Distribution)를 히스토그램 형태로 보여줍니다.


이 값들의 분포를 보는 것이 중요한 이유는 훈련 중에 파라미터 값이 너무 커지거나(Exploding), 너무 작아져 0에 가까워지는(Vanishing) 현상이 없는지 확인할 수 있습니다.
파라미터 분포가 예쁘게 잘 유지되는지 보는 것이죠. 슬라이더(Step)를 움직여 훈련 진행에 따라 분포가 어떻게 변하는지 관찰할 수 있습니다.
마지막으로 가장 아래쪽에는 Train동안에 각종 System Resource들이 변화 추이를 그래프로 보여줍니다.

3.3. Sweep
Sweep은 Train시에 Hyperparameter를 미리 설정한 값들을 바탕으로 자동으로 변경해가며 최적의 값을 찾는 기능입니다.
순서대로 하나씩 알아보도록 하겠습니다.
1) Sweep 설정 정의 (YAML 파일)
어떤 하이퍼파라미터들을 탐색할지 (예: learning rate, batch size, optimizer 종류 등)와 각 파라미터의 탐색 범위 또는 값 목록을 정의하고, 어떤 탐색 전략((Ex. Grid Search, Random Search, Bayesian Optimization)을 사용할지 선택해야 합니다.
또한, 어떤 Metric((Ex. val_accuracy를 maximize 또는 val_loss를 minimize)를 최적화할 것인지, 실행할 Train Code 파일명을 지정합니다.
이 모든 설정을 보통 .yaml 파일에 작성합니다.
아래와 같은 yaml 파일을 이용해서 Test해 보도록 하겠습니다.
program: wandb_Test.py # 실행할 Train Code 파일명
method: bayes # 탐색 방법: grid, random, bayes 중 선택
metric:
name: val_accuracy # 최적화 목표 지표 이름 (wandb.log로 기록되는 이름)
goal: maximize # 목표: maximize 또는 minimize
parameters:
optimizer:
values: ["Adam", "SGD"] # 시도해볼 Optimizer 종류
learning_rate:
distribution: uniform # 분포 방식 (균등 분포)
min: 0.0001 # 최소 학습률
max: 0.01 # 최대 학습률
batch_size:
values: [64, 128, 512] # 시도해볼 배치 크기
epochs:
value: 5 # 에폭 수 (튜닝 대상이 아닙니다)
참고로, Train Code는 Python File(.py)만 사용할 수 있습니다.
이유는 하이퍼파라미터 값들을 명령줄 인자(argument) 형태로 전달하기 때문에 Jupyter Notebook은 실행이 되지 않아요.
그리고, 설정값들 중에 중요한 것중의 하나가 최적의 하이퍼파라미터들을 탐색하는 전략인데요, 총 3가지가 있습니다.
1. Grid Search
사용자가 지정한 하이퍼파라미터 값들의 모든 가능한 조합을 하나씩 다 시도합니다.
예를 들어 learning rate를 [0.1, 0.01], batch size를 [32, 64]로 지정하면 (0.1, 32), (0.1, 64), (0.01, 32), (0.01, 64)의 4가지 조합을 모두 실행합니다.
매우 체계적이고 모든 조합을 탐색하지만, 파라미터 개수나 값의 종류가 많아지면 시도해야 할 조합의 수가 기하급수적으로 늘어나 매우 비효율적입니다 (차원의 저주).
이해하기 쉽게 흔히 말하는 "brute force" 방식입니다.
2. Random Search
사용자가 지정한 하이퍼파라미터의 범위나 분포 내에서 무작위로 값을 샘플링하여 조합을 만들고 시도하며, 몇 번의 시도(run)를 할지 지정할 수 있습니다.
Grid Search보다 훨씬 효율적입니다. 실제로 중요한 하이퍼파라미터는 소수일 경우가 많은데, Random Search는 다양한 값들을 탐색하며 좋은 조합을 더 빨리 찾을 가능성이 높습니다.
Grid Search처럼 모든 조합을 다 시도하지는 않습니다.
3. Bayesian Optimization(추천)
이전 실험 결과(하이퍼파라미터 조합과 그 성능)를 학습하여, 다음번에는 더 좋은 성능을 낼 가능성이 높은 하이퍼파라미터 조합을 지능적으로 예측하고 시도합니다.
확률 모델(주로 가우시안 프로세스)을 사용하여 탐색(Exploration)과 활용(Exploitation) 사이의 균형을 맞춥니다.
Grid Search나 Random Search보다 적은 시도 횟수로도 좋은 성능의 하이퍼파라미터 조합을 찾을 가능성이 가장 높습니다.
특히 탐색 공간이 크거나 한 번의 실험 비용(시간, 리소스)이 비쌀 때 매우 유용합니다. 하지만 내부적으로 더 복잡한 계산이 필요합니다.
만약 Train Code내부에 자체적으로 Learning rate scheduler가 있고, Sweep의 설정파일에서도 Learning rate 분포를 설정하게 되면 어떻게 될까요?
결과적으로 개별적으로 동작합니다. 즉, Sweep에서 설정한 Learning rate가 먼저 Train Code에 전달되고 이 값을 Train Code내부의 Learning rate scheduler에서 받아서 자체적으로 Learning rate scheduler가 작동하게 되는 원리입니다.
2) Sweep Controller 초기화
다음으로 터미널에서 wandb sweep <설정파일.yaml> 명령어를 실행하여 wandb 서버에 Sweep 작업을 생성합니다.
이렇게 하면 wandb는 고유한 sweep_id를 반환하는데, 이 ID는 이 특정 Sweep 작업을 식별하는 데 사용됩니다.

3) Agent 실행
위 그림에서 노란색 부분의 명령어를 실행하면 Agent가 실행되면서 Sweep이 실행되기 시작합니다.
명령어를 실행하면 Agent는 wandb 서버에 접속하여 다음 실험에 사용할 하이퍼파라미터 조합을 받아옵니다.
Agent는 받아온 하이퍼파라미터 설정을 사용하여 1번에서 지정한 Train Code를 실행하게 되는 것이죠
Train Code 내의 wandb.init()은 Agent에 의해 실행될 때 자동으로 Sweep 설정을 인식하고 wandb.config에 해당 실험의 하이퍼파라미터를 설정해줍니다.
따라서 Train Code는 거의 수정할 필요 없이 wandb.config를 통해 하이퍼파라미터를 읽어오기만 하면 됩니다.

훈련이 끝나면 Agent는 결과를 wandb 서버에 보고하고, 다시 다음 하이퍼파라미터 조합을 받아와 실험을 계속 반복합니다.
여러 개의 Agent를 동시에 실행하여 병렬로 하이퍼파라미터 탐색을 수행할 수도 있습니다.
(각 Agent는 서로 다른 하이퍼파라미터 조합을 받아서 실행)

4) 결과 확인
Sweep 동작은 탐색 전략을 Grid Search로 지정하지 않은 이상 저절로 멈추지 않습니다.
그래서, 사용자가 직접 CLI에서 Ctrl-C를 눌러서 Sweep 동작을 멈추어야합니다.
대신, agent 실행시에 --count N Option을 이용해서 최대 동작 횟수를 지정할 수는 있습니다.
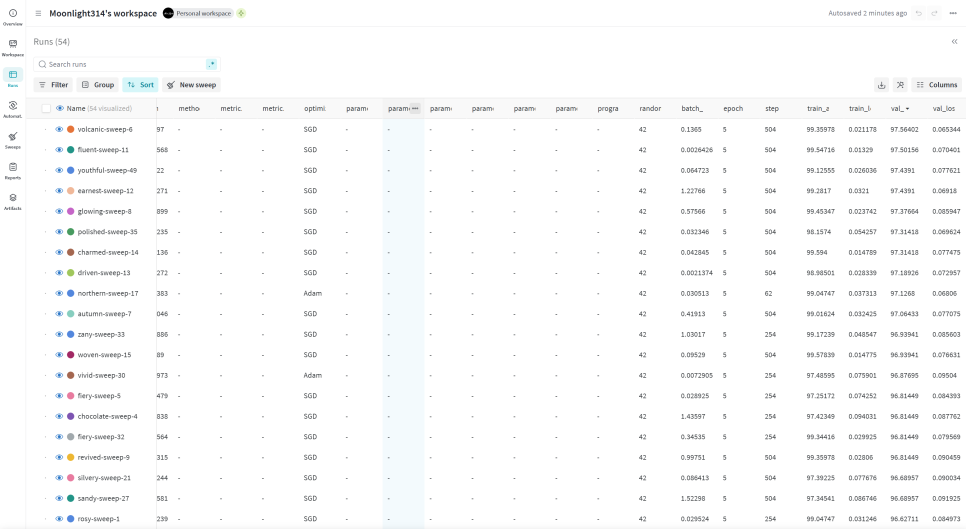
Sweep을 마무리하고 wandb site에 보면 각 Run의 결과가 정리되어 있습니다.
이를 통해서 어떤 조합의 Hyperparameter가 가장 좋은 성능을 내는지 확인할 수도 있고, 이 결과를 다른 팀원들과 공유할 수도 있으며 Report 작성도 가능합니다.


도움이 되셨으면 좋겠네요. 읽어주셔서 감사합니다.
'Deep_Learning' 카테고리의 다른 글
| Example of SFT(Supervised Fine-Tuning) Trainer in TRL (2) | 2025.06.07 |
|---|---|
| TRL (Transformer Reinforcement Learning) (6) | 2025.06.07 |
| Alignment in LLM (0) | 2025.05.13 |
| Downstream in LLM (0) | 2025.04.19 |
| DeepSeek-VL : Towards Real-World Vision-Language Understanding (0) | 2025.04.19 |