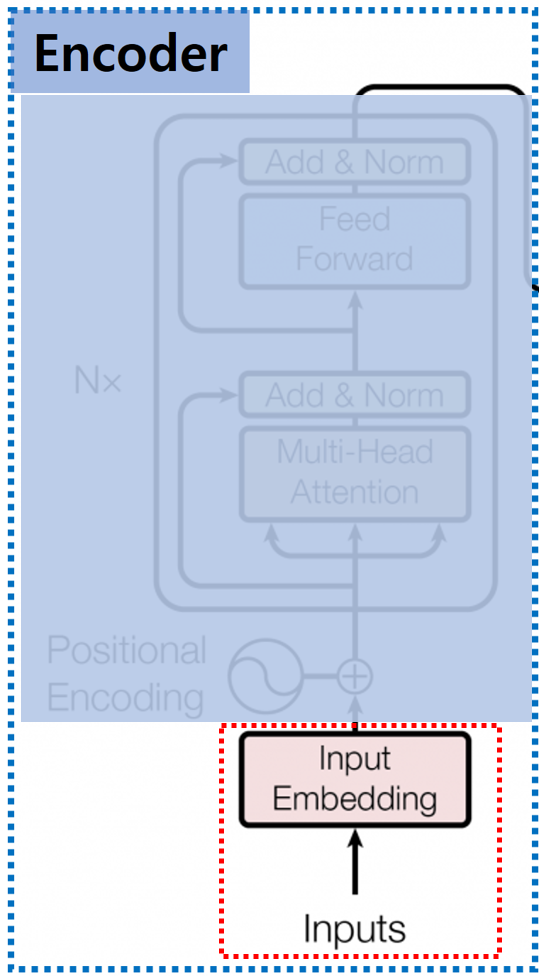
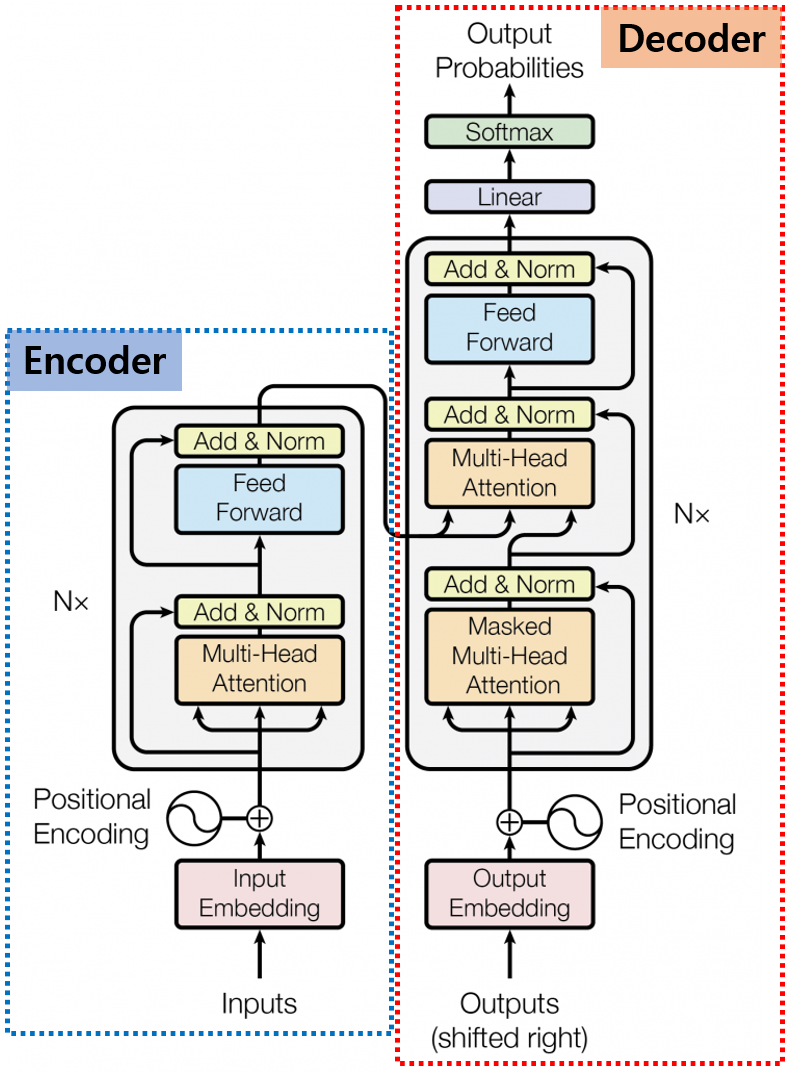
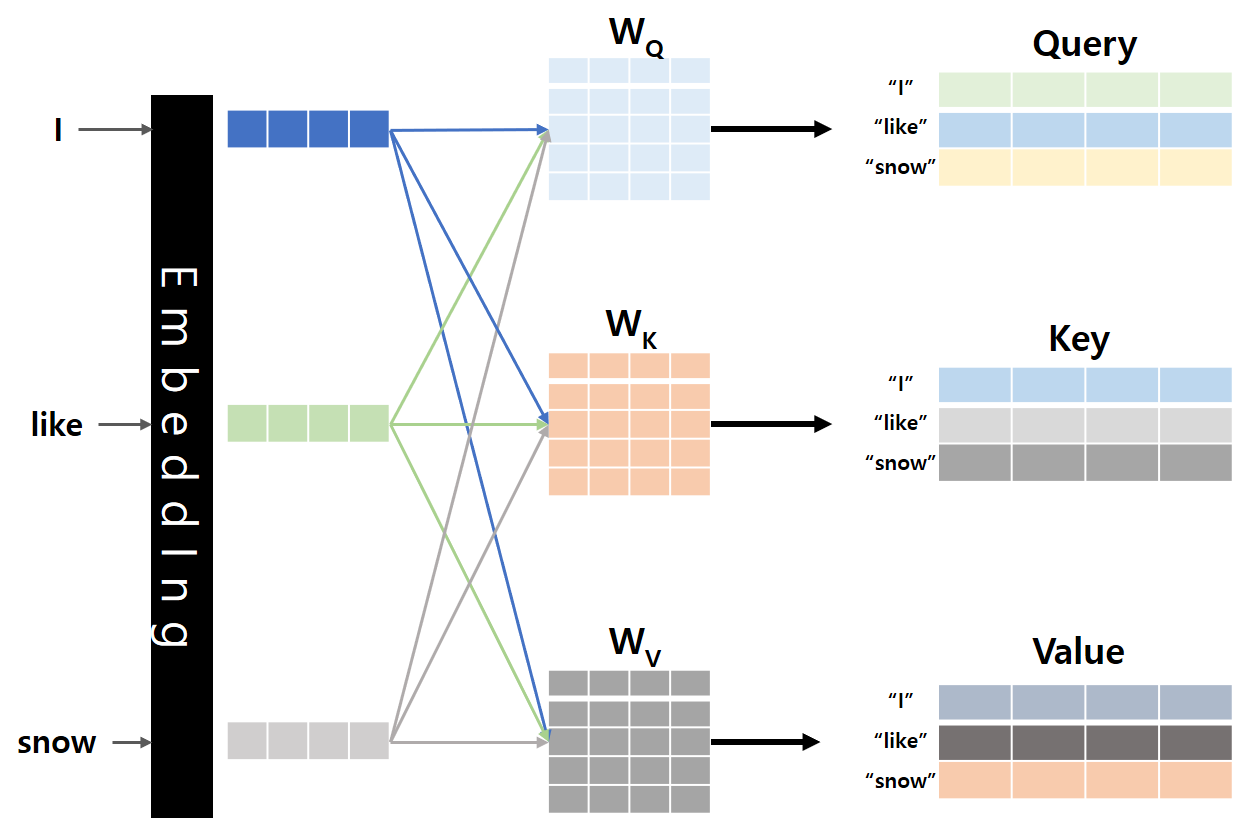
안녕하세요, MoonLight입니다.이번 Post에서는 LLM을 Fine-tuning하고 Rreinforcement learning을 적용하는 데 사용되는 도구 모음인 TRL(Transformer Reinforcement Learning)에 대해서 알아보도록 하겠습니다. 1. LLM Alignment 필요성 2017년 "Attention Is All You Need"라는 논문으로 Transformer라는 구조가 세상에 나왔고, 이 Transformer 구조를 기반으로 하는 LLM들이 방대한 데이터로 비지도 학습(Unsupervised Learning) 방식으로 사전 훈련(Pre-training)되어 광범위한 세계 지식과 추론 능력을 학습하였습니다.하지만, Pre-training만으로는 LLM..